Today's message is really simply. Please consider it, when in doubt whether to apply webservices or not:
"Webservices are for integration, not for inter-tier distribution."
This also goes to all .NET and Java consultants out there, who like to present one-click webservice-creation in VS.NET or WSAD: Please don't forget to remind your audience about it. I know that some of you didn't, that's why a lot of people who want to place the webservice-badge on their intranet application now put their whole business layer behind webservices (instead of EJBs (over RMI/IIOP) resp. COM+ services (over DCOM), or no distribution at all using a simple business facade and plain DTOs, or whatever other better-suited solution).
Webservice PROs and CONs
(+) Interoperability between various software applications running on different platforms and/or locations.
(+) Enforces open standards and protocols.
(+) HTTP will go through firewalls with standard filtering rules.
(+) Enables loose coupling (when using Document- instead of RPC-style resp. XML extensibility).
(-) Features such as transactions are either nonexistent or still in their infancy compared to more mature distributed computing standards such as RMI, CORBA, or DCOM.
(-) Poor performance in comparison to other approaches (lower network throughput because of text-based data, XML parsing / transformation required).
This implies: When there is no need for platform interop and firewall pass-through, but for things like high performance and transaction monitoring, don't use webservices as your main business layer protocol. You can still selectively publish webservices to the outside world, which may then call into your business layer (J2EE and COM+ offer direct support on that, e.g. direct mapping to Enterprise Service facades resp. Session Bean facades). But if it's just your intranet client or your web application calling into your business layer, please don't let each call run through the complete SOAP stack.
Things can get even worse than that: Because more and more people practice senseless and blind technology-overuse, there is a project out there where report layouts are being downloaded to the client embedded in .NET assemblies marshalled as byte-arrays over webservices, all of this within one corporate network (where there is no need for interoperability (all is done in .NET) nor HTTP). No kidding. This is for real.

Saturday, July 30, 2005
Tuesday, July 26, 2005
Please, Do Not String-Concatenate SQL-Parameters
No reason to be surprised that code like this one not only exists in old legacy applications, but also still is being produced on a daily basis - as long one of the most widespread German .NET developer magazines publishes articles like that:
Sonderzeichen in SQL-Kommandos unter ADO.NET
INSERT Murks? Möglicherweise haben Sie es noch gar nicht bemerkt, aber wenn Sie mithilfe von SQL-Anweisungen Texte in Datenbanken eintragen, spielt deren Zusammensetzung eine entscheidende Rolle. Bestimmte Sonderzeichen verwirren ADO.NET, und der SQL-Aufruf kann scheitern. Mit einem einfachen Trick sichern Sie sich ab.
The author then suggests a string-replacement approach in order to manually escape apostrophs when using ADO.NET'S SQLServer Provider. For those of you who are interested, a single ' will be escaped to '' (SQLServer's usual escaping schema for apostrophs).
So he argues apostrophs might brake SQL statements, e.g. on statements like this:
and instead recommends something like:
Now if
Here is how developers with some common sense (as opposed to overpaid consultants who have no idea about real-life projects) are going to handle that: Obviously we prefer to externalize out SQL-code somewhere else, e.g. in our own XML-structure, and embed that XML-file in our assembly. We won't leave SQL lying inside C# code, so we will never even feel the urge to merge those two. And we keep our hands off VS.NET's SQL Query wizard - it just produces unreadable and unmaintainable code. We don't really need a wizard to assemble SQLs, now do we? (if we would, we'd better better get back to Access). And of course, and this is the main point here, we take advantage of parameter placeholders, so ADO.NET will take care of expanding them properly into the statement (and SQLServer will receive the strongly typed values and at the same time can prevent SQL injection) .
How was our expert here going to insert DataTime values (which format pattern to use?), or GUIDs, or BLOBS, or... and with is string-concatenation approach he opens all doors for SQL-injection. Plus he locks in on specific SQLServer collation settings (they'd better never change in the future).
So please, don't bother with solutions for problems that don't even exist.
Sonderzeichen in SQL-Kommandos unter ADO.NET
INSERT Murks? Möglicherweise haben Sie es noch gar nicht bemerkt, aber wenn Sie mithilfe von SQL-Anweisungen Texte in Datenbanken eintragen, spielt deren Zusammensetzung eine entscheidende Rolle. Bestimmte Sonderzeichen verwirren ADO.NET, und der SQL-Aufruf kann scheitern. Mit einem einfachen Trick sichern Sie sich ab.
The author then suggests a string-replacement approach in order to manually escape apostrophs when using ADO.NET'S SQLServer Provider. For those of you who are interested, a single ' will be escaped to '' (SQLServer's usual escaping schema for apostrophs).
So he argues apostrophs might brake SQL statements, e.g. on statements like this:
string sql = "select * from dotnet_authors where clue > 0 or name <> '" + yournamegoeshere + "'";and instead recommends something like:
string sql = "select * from dotnet_authors where clue > 0 or name <> '" + MyCoolEscapingMethod(yournamegoeshere) + "'";Now if
yournamegoeshere contains an apostroph, yes the former command will fail. But who on earth would voluntarily code SQL like this anyway?Here is how developers with some common sense (as opposed to overpaid consultants who have no idea about real-life projects) are going to handle that: Obviously we prefer to externalize out SQL-code somewhere else, e.g. in our own XML-structure, and embed that XML-file in our assembly. We won't leave SQL lying inside C# code, so we will never even feel the urge to merge those two. And we keep our hands off VS.NET's SQL Query wizard - it just produces unreadable and unmaintainable code. We don't really need a wizard to assemble SQLs, now do we? (if we would, we'd better better get back to Access). And of course, and this is the main point here, we take advantage of parameter placeholders, so ADO.NET will take care of expanding them properly into the statement (and SQLServer will receive the strongly typed values and at the same time can prevent SQL injection) .
<sql><![CDATA[
select * from dotnet_authors where clue > 0 or name <> @yournamegoeshere
]]></sql>How was our expert here going to insert DataTime values (which format pattern to use?), or GUIDs, or BLOBS, or... and with is string-concatenation approach he opens all doors for SQL-injection. Plus he locks in on specific SQLServer collation settings (they'd better never change in the future).
So please, don't bother with solutions for problems that don't even exist.
EBay, What Have You Done?
As you certainly know, decimal delimiters and thousand separators differ depending on locale settings. While US-Americans expect something like this
USD 1,000.00
... on a German locale, the same amount is formatted like that
USD 1.000,00
Fair enough. One might expect that EBay is capable of handling those little local differences on their global marketplace. BUT THEY DON'T! In their opinion
USD 49,99
USD 20,00
USD 10,00
... adds up to:
USD 1.069,99
If Donald Knuth could only see what people charge for "The Art Of Computer Programming" nowadays. ;-)
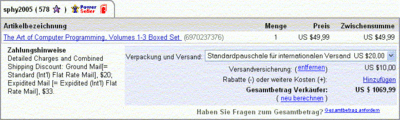
Sorry for the poor image quality, all I had around at that time was Microsoft Photoeditor - no idea why it thinks it has to dither solid color image data.
Reminds me of one former colleague who insisted on writing the decimal value formatter and parser for our monetary input fields (he claimed to have experience from his previous work on ATM terminals - good lord!). If you tabbed through his fields without actually typing something, the value would change (his formatting and parsing algorithms were, well, inconsistent) - e.g. on the first FocusLost from an original input of "10,0" to "100" (?!?) and on the next FocusLost further to "100.00". Looked funny, but just as long as no customer would ever get to see it. Luckily we got rid of it quite early in the project.
Yes, those were the days of Java 1.0 (before java.text.NumberFormat even existed - if I remember correctly it came along with JDK1.1).
USD 1,000.00
... on a German locale, the same amount is formatted like that
USD 1.000,00
Fair enough. One might expect that EBay is capable of handling those little local differences on their global marketplace. BUT THEY DON'T! In their opinion
USD 49,99
USD 20,00
USD 10,00
... adds up to:
USD 1.069,99
If Donald Knuth could only see what people charge for "The Art Of Computer Programming" nowadays. ;-)
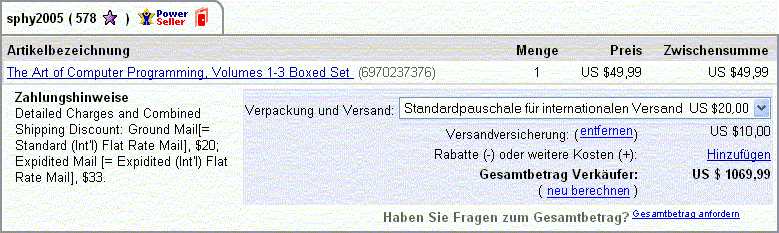
Reminds me of one former colleague who insisted on writing the decimal value formatter and parser for our monetary input fields (he claimed to have experience from his previous work on ATM terminals - good lord!). If you tabbed through his fields without actually typing something, the value would change (his formatting and parsing algorithms were, well, inconsistent) - e.g. on the first FocusLost from an original input of "10,0" to "100" (?!?) and on the next FocusLost further to "100.00". Looked funny, but just as long as no customer would ever get to see it. Luckily we got rid of it quite early in the project.
Yes, those were the days of Java 1.0 (before java.text.NumberFormat even existed - if I remember correctly it came along with JDK1.1).
Monday, July 25, 2005
In Praise Of EJBs
Ted Neward replies to Floyd Marinescu's brief EJB retrospection, and I kind of follow his line of arguments. On the largest web application that I have worked on that included EJBs, we did physically split Web-container and EJB-container, and invoked methods on a lightweight stateful Session Bean's remote interface on each request. All further calls to Session (all of them stateless) and Entity Beans went through local interfaces. Thus, each client session kept its own Session Bean context, and all other EJBs referenced from there on would run in the same address space. So physical distribution happened following this design - and the EJB container would decide which node would actually hold the Session Bean (depending on the current workload).
One common (mis-)perception goes that EJBs are too heavyweight (but then, what does "heavyweight" refer to? The API? Metadata AKA Deployment Descriptors? Runtime overhead?), so specifically the Entity Bean specs have been gone through several stages of modification, particularly in the latest EJB version 3.0. My opinion: those constant changes did more harm than good, more then anything else the discussions around EJB 3.0 created fear, uncertainty and doubt among J2EE developers when it comes to container-managed Entity Beans (CMP EJBs are no rocket science either, and yes, they do scale well - what about your third party O/R mapper?).
I always considered EJB 2.0 a fairly well-balanced approach. The complexity was still manageable, and the developer could always decide whether to go a bean-managed ("do it yourself") or container-managed ("let the container take care of it") way of handling persistence, transaction-management, security and the like.
More than that, EJBs represent a clear guidance of how to architect J2EE applications within the business logic and data access layers (JSP Model 2 completed this on the user interface side). No more self-made infrastructure code, or the need for purchasing arcane third party application server infrastructure platforms or obscure persistence frameworks (it's hard to believe how many software vendors still fall into this trap, just because of their lacking enterprise application know-how, and the "stupidly-follow-the-consultant-piper-who-only-tries-to-sell-his-own-product"-syndrome).
Instead, choose your J2EE vendor (or even free alternatives, like JBoss or OpenEJB), so you can concentrate on building your application logic. There are really cool EJB-oriented IDEs out there (IBM's Websphere Application Developer does a great job here). And there is more than enough literature on EJB patterns and strategies, which should also helpt to limit the risk of doing things fundamentally wrong.
One common (mis-)perception goes that EJBs are too heavyweight (but then, what does "heavyweight" refer to? The API? Metadata AKA Deployment Descriptors? Runtime overhead?), so specifically the Entity Bean specs have been gone through several stages of modification, particularly in the latest EJB version 3.0. My opinion: those constant changes did more harm than good, more then anything else the discussions around EJB 3.0 created fear, uncertainty and doubt among J2EE developers when it comes to container-managed Entity Beans (CMP EJBs are no rocket science either, and yes, they do scale well - what about your third party O/R mapper?).
I always considered EJB 2.0 a fairly well-balanced approach. The complexity was still manageable, and the developer could always decide whether to go a bean-managed ("do it yourself") or container-managed ("let the container take care of it") way of handling persistence, transaction-management, security and the like.
More than that, EJBs represent a clear guidance of how to architect J2EE applications within the business logic and data access layers (JSP Model 2 completed this on the user interface side). No more self-made infrastructure code, or the need for purchasing arcane third party application server infrastructure platforms or obscure persistence frameworks (it's hard to believe how many software vendors still fall into this trap, just because of their lacking enterprise application know-how, and the "stupidly-follow-the-consultant-piper-who-only-tries-to-sell-his-own-product"-syndrome).
Instead, choose your J2EE vendor (or even free alternatives, like JBoss or OpenEJB), so you can concentrate on building your application logic. There are really cool EJB-oriented IDEs out there (IBM's Websphere Application Developer does a great job here). And there is more than enough literature on EJB patterns and strategies, which should also helpt to limit the risk of doing things fundamentally wrong.
Saturday, July 16, 2005
AJAX Or The Return Of JavaScript
Regarding all that AJAX ("Asynchronous JavaScript and XML") hype that spread around lately (which came along with a new kind of web applications, see GMail, Google Maps, Flickr and the like) I wonder whether server-side gui-event processing (e.g. as propagated by ASP.NET) has come to an end, or if both approaches will co-exist side-by-side in the future. To me, AJAX seems to have some clear advantages on the user-experience level. On the other hand, AJAX denotes an approach, not a standard, so the question arises which AJAX base library to use.
What's interesting to note is that probably the main technology enabler for AJAX was the introduction of the JavaScript XMLHttpRequest class, which originally came from Microsoft (ActiveX's "Microsoft.XMLHTTP"). Mozilla, Safari and other browsers followed with more or less identical implementations. Another proof that - yes indeed - Microsoft DOES innovate.
For me this means to revamp my somewhat dusty JavaScript knowledge (JavaScript 1.2 was were I stopped - enough to do some simple client-side stuff that did not require server round-trips, and was available on all browsers - but certainly not enough for building AJAX applications).
What's interesting to note is that probably the main technology enabler for AJAX was the introduction of the JavaScript XMLHttpRequest class, which originally came from Microsoft (ActiveX's "Microsoft.XMLHTTP"). Mozilla, Safari and other browsers followed with more or less identical implementations. Another proof that - yes indeed - Microsoft DOES innovate.
For me this means to revamp my somewhat dusty JavaScript knowledge (JavaScript 1.2 was were I stopped - enough to do some simple client-side stuff that did not require server round-trips, and was available on all browsers - but certainly not enough for building AJAX applications).
Monday, July 11, 2005
A.K. Has Little Patience...
... with colleagues apparently not at his level of knowledge.
My experience is: while people lacking some qualification might indeed be dreadful to software projects, even worse are the folks who think they know and make their seniors (who are most likely even more clueless) believe so too, hence are then put in charge of things they should better leave their hands off.
I once was shown some old Java code originating from a guy who used to be the organizations' only person with little above zero Java/XML/HTTP-knowledge. He managed to make that Java system Unicode-inapt (now that's a real accomplishment on a platform that is Unicode-able per definition), wrote his own, broken XML-parser/-transformer which produced whatever format but not XML (ignoring the fact that JAXP has been part of the JDK since version 1.3 - the poor maintenance programmes suffered for years to come, as they could not use real XML on the other side of the pipe either), and even implemented his own HTTP on top of TCP sockets (or what would be a poor man's HTTP: writing "GET [someurl]" to a socket stream and reading the response), just because he didn't know how to send HTTP headers using Java's HTTP API (of course a complete HTTP implementation is part of every Java version since 1995). Back then he was the proclaimed Java expert on that very group (as everyone else there was coding VB or whatever), hence was given plenty of rope, and consequently screwed up.
I prefer coworkers who admit they don't know too much about a certain technology, but are willing to learn and to listen. Give them easy tasks at first, support them, and let them grow step by step. Programming is no rocket science, and no brain surgery either. Heck there are so many things even inside my area of expertise that I don't know much of. But I know that I don't know, and I know whom to ask or how to learn when required.
But if A.K.'s colleague is an idiot and not willing to change something about it, I offer my condolences.
My experience is: while people lacking some qualification might indeed be dreadful to software projects, even worse are the folks who think they know and make their seniors (who are most likely even more clueless) believe so too, hence are then put in charge of things they should better leave their hands off.
I once was shown some old Java code originating from a guy who used to be the organizations' only person with little above zero Java/XML/HTTP-knowledge. He managed to make that Java system Unicode-inapt (now that's a real accomplishment on a platform that is Unicode-able per definition), wrote his own, broken XML-parser/-transformer which produced whatever format but not XML (ignoring the fact that JAXP has been part of the JDK since version 1.3 - the poor maintenance programmes suffered for years to come, as they could not use real XML on the other side of the pipe either), and even implemented his own HTTP on top of TCP sockets (or what would be a poor man's HTTP: writing "GET [someurl]" to a socket stream and reading the response), just because he didn't know how to send HTTP headers using Java's HTTP API (of course a complete HTTP implementation is part of every Java version since 1995). Back then he was the proclaimed Java expert on that very group (as everyone else there was coding VB or whatever), hence was given plenty of rope, and consequently screwed up.
I prefer coworkers who admit they don't know too much about a certain technology, but are willing to learn and to listen. Give them easy tasks at first, support them, and let them grow step by step. Programming is no rocket science, and no brain surgery either. Heck there are so many things even inside my area of expertise that I don't know much of. But I know that I don't know, and I know whom to ask or how to learn when required.
But if A.K.'s colleague is an idiot and not willing to change something about it, I offer my condolences.
Bugtracking With Track+
I have been looking for some decent, easy-to-use bugtracking software lately for one of our projects. My first recommondations were Bugzilla and Mantis, simply because I knew them from the past and they were freely available. But their installation procedures (e.g. Perl, MySQL as prerequisites for Bugzilla) overstrained the sysadmin responsible for setting up and maintaining the server (external staff - to his defense, he had no experience in these areas). Plus I never liked Bugzilla's nor Mantis' user interface.
So I continued searching, and finally found Track+. Originally a Sourceforge project, the licensing model was very attractive (free license for up to ten users), the featureset looked good, it supported all kinds of operating systems and databases, and it came with a complete Windows installer. I did a test installation and had it up and running in ten minutes.
The only prerequisite is an existing JDK1.4.2. The setup package also provides Tomcat 5 as web/application container and the free Firebird database. I only had to add tools.jar to Tomcat's classpath (seems as if the installer forgot about that - otherwise Tomcat's JSP engine Jasper would not be able to compile JSP pages).
We will do some more testing and will most likely move our old bugtracking data over to Track+ if it continues to work that smoothly.
So I continued searching, and finally found Track+. Originally a Sourceforge project, the licensing model was very attractive (free license for up to ten users), the featureset looked good, it supported all kinds of operating systems and databases, and it came with a complete Windows installer. I did a test installation and had it up and running in ten minutes.
The only prerequisite is an existing JDK1.4.2. The setup package also provides Tomcat 5 as web/application container and the free Firebird database. I only had to add tools.jar to Tomcat's classpath (seems as if the installer forgot about that - otherwise Tomcat's JSP engine Jasper would not be able to compile JSP pages).
We will do some more testing and will most likely move our old bugtracking data over to Track+ if it continues to work that smoothly.
Tuesday, July 05, 2005
The Next SQL WTF: Where-Unaware Select
Alex Papadimoulis writes: "There was a time where I used to believe that the worst possible way one could retrieve rows from a table was to SELECT the entire table, iterate through the rows, and test a column to see if it matched some critera; ..."
Another infamous SQL WTF: The Where-Unaware Select - woooha, makes me shiver...
By the way, if you think selecting a whole table into memory and scanning through each row programmatically just must be unreal - that's exactly what one of those framework astronauts recommended in a real-life project I know of, where people were forced to use his blasted O/R-mapper. No need to say the project was canceled months later...
Another infamous SQL WTF: The Where-Unaware Select - woooha, makes me shiver...
By the way, if you think selecting a whole table into memory and scanning through each row programmatically just must be unreal - that's exactly what one of those framework astronauts recommended in a real-life project I know of, where people were forced to use his blasted O/R-mapper. No need to say the project was canceled months later...
The Best Software Writing
Today I received my copy of Joel Spolsky's "The Best Software Writing", a collection of software essays (mainly blog articles, hand-selected by the readers of Joel On Software, resp. Joel himself).

I even ordered this book in the States, as it had not been available in Europe at that time. Highly recommended reading material!
I even ordered this book in the States, as it had not been available in Europe at that time. Highly recommended reading material!
Saturday, July 02, 2005
Pragmatic Solutions For An Imperfect World
Some time ago, with only one week to go until the scheduled delivery deadline of our .NET client/server product, our customer reported increasing application instability. My developers had not observed that issue so far, but the application seemed to crash sporadically (but unrepeatably) on our customer's test machines. As we were coding in managed C# only, my first guess was a .NET runtime failure, or a native third party library bug. Luckily, we had installed some post-mortem tracer, which turned out the following exception stacktrace:
Great. Win32 API's PeekMessage() failing, and the failure being mapped to a .NET NullReferenceException. I was starting to get nervous.
I told our customer that our code was not involved (it's always good to be able to blame someone else). But as expected this answer was less-than-satisfying. The end-user couldn't care less about who was guilty, and so did our customer (and they are right to do so). They wanted a solution, and they wanted it fast.
Now I have some faith in Microsoft's implementation of PeekMessage(). It seems to work quite well in general (let's say in all Windows applications that run a message queue) - so something must have been messed up before, with PeekMessage() failing as a result of that. Something running in native code. Something like our report engine (no, it's not Crystal Reports).
We had not invoked our reports too frequently during our normal test runs, as the report layouts and SQL-statements are being done by our customer. So after some report stress testing, those crashes also occurred on our machines. Rarely, but they did. And they occurred asynchronously, within seconds after the last report invocation. Here was the next hint. This was a timing problem, most likely provoked during garbage collection.
So how to prove or disprove this theory? I simply threw all reporting instances into one large ArrayList, so that those would never be picked up by the garbage collector (SIDENOTE: NEVER DO THIS IN A REAL-LIFE PROJECT), and voila: no more crashes, even after hours of stress testing. Obviously keeping all reporting instances in memory introduces a veritable memory leak (still better than a crashing application someone might argue, but this is something I never ever want to see in any implementation I am responsible for). But I had a point of attack: the reporting instances (or one of the objects being referenced by those instances) failed when their Finalizers were invoked.
First of all I noticed that the reporting class (a thin managed .NET wrapper around the reporting engine's native implementation) implemented IDisposable - so I checked all calling code for correct usage (means invocation of Dispose(), most comfortably by applying C#'s "using" construct). When implemented properly, this should prevent a second call to Dispose() during finalization, which might be the root of evil. But our code seemed to be OK.
Next I hard-coded GC.SuppressFinalize() for all reporting instances that had been disposed already, in order to prevent the call to its Destructor (Finalizer in .NET terms) as well, but still no cure - obviously it was not the reporting instance itself that crashed during finalization, but another object referenced by the reporting instance. I ran Lutz Roeder's Reflector, and had a look at all the reporting .NET classes, resp. their Dispose()- and Finalizer-Methods: they only wrapped away native code.
If I could only postpone those Finalizer-calls until as late as necessary (e.g. until free'ing their memory was an absolute must - native resources would not be the problem, as they would be cleaned up long before during the synchronous call to Dispose()). The moment the application would run out of memory even after conventional garbage collection (which might never happen), it would collect the reporting instances. I needed SoftReferences. The garbage collector delays the collection of objects referenced by SoftReferences as long as possible. Unfortunately, .NET does not provide the concept of SoftReferences (Java does, though). .NET has WeakReferences, which will be picked up much earlier than SoftReferences. So I simply started my own background thread, which would remove reporting instances from a static Collection after some minutes of reporting inactivity, hence make them available for garbage collection.
Sometimes luck just strikes me, and that's what happened here: this approach extinguished all sudden crashes. The reporting instances got picked up by the garbage collector (I debugged that), but just a little bit later. Late enough for their finalization to run smoothly. So up to now I don't know the exact cause (as mentioned before, it must have been a timing problem - if reporting instances survive some seconds, they will not crash during finalization). We are still investigating it, and we will find a more suitable fix. But much more important: we shipped on time, and we made our customer happy. All end-user installations are working fine so far.
Do I like the current solution? No, it's a hack. But still it's 10.000 times better than shipping an unstable product. From a certain level of complexity on, all software products contain hacks. Just have a look at the Windows 2000 source (esp. the code comments) that were spread on P2P-networks some time ago. In an imperfect world, you sometimes have to settle with imperfect (but working) solutions for your problems.
Unhandled Exception: System.NullReferenceException: Object reference not set to an instance of an object.
at System.Windows.Forms.UnsafeNativeMethods.PeekMessage(MSG& msg, HandleRef hwnd, Int32 msgMin, Int32 msgMax, Int32 remove)
at System.Windows.Forms.ComponentManager.
System.Windows.Forms.UnsafeNativeMethods+
IMsoComponentManager.FPushMessageLoop
(Int32 dwComponentID, Int32 reason, Int32 pvLoopData)
at System.Windows.Forms.ThreadContext.RunMessageLoopInner(Int32 reason, ApplicationContext context)
at System.Windows.Forms.ThreadContext.RunMessageLoop(Int32 reason, ApplicationContext context)
at System.Windows.Forms.Application.Run(Form mainForm)Great. Win32 API's PeekMessage() failing, and the failure being mapped to a .NET NullReferenceException. I was starting to get nervous.
I told our customer that our code was not involved (it's always good to be able to blame someone else). But as expected this answer was less-than-satisfying. The end-user couldn't care less about who was guilty, and so did our customer (and they are right to do so). They wanted a solution, and they wanted it fast.
Now I have some faith in Microsoft's implementation of PeekMessage(). It seems to work quite well in general (let's say in all Windows applications that run a message queue) - so something must have been messed up before, with PeekMessage() failing as a result of that. Something running in native code. Something like our report engine (no, it's not Crystal Reports).
We had not invoked our reports too frequently during our normal test runs, as the report layouts and SQL-statements are being done by our customer. So after some report stress testing, those crashes also occurred on our machines. Rarely, but they did. And they occurred asynchronously, within seconds after the last report invocation. Here was the next hint. This was a timing problem, most likely provoked during garbage collection.
So how to prove or disprove this theory? I simply threw all reporting instances into one large ArrayList, so that those would never be picked up by the garbage collector (SIDENOTE: NEVER DO THIS IN A REAL-LIFE PROJECT), and voila: no more crashes, even after hours of stress testing. Obviously keeping all reporting instances in memory introduces a veritable memory leak (still better than a crashing application someone might argue, but this is something I never ever want to see in any implementation I am responsible for). But I had a point of attack: the reporting instances (or one of the objects being referenced by those instances) failed when their Finalizers were invoked.
First of all I noticed that the reporting class (a thin managed .NET wrapper around the reporting engine's native implementation) implemented IDisposable - so I checked all calling code for correct usage (means invocation of Dispose(), most comfortably by applying C#'s "using" construct). When implemented properly, this should prevent a second call to Dispose() during finalization, which might be the root of evil. But our code seemed to be OK.
Next I hard-coded GC.SuppressFinalize() for all reporting instances that had been disposed already, in order to prevent the call to its Destructor (Finalizer in .NET terms) as well, but still no cure - obviously it was not the reporting instance itself that crashed during finalization, but another object referenced by the reporting instance. I ran Lutz Roeder's Reflector, and had a look at all the reporting .NET classes, resp. their Dispose()- and Finalizer-Methods: they only wrapped away native code.
If I could only postpone those Finalizer-calls until as late as necessary (e.g. until free'ing their memory was an absolute must - native resources would not be the problem, as they would be cleaned up long before during the synchronous call to Dispose()). The moment the application would run out of memory even after conventional garbage collection (which might never happen), it would collect the reporting instances. I needed SoftReferences. The garbage collector delays the collection of objects referenced by SoftReferences as long as possible. Unfortunately, .NET does not provide the concept of SoftReferences (Java does, though). .NET has WeakReferences, which will be picked up much earlier than SoftReferences. So I simply started my own background thread, which would remove reporting instances from a static Collection after some minutes of reporting inactivity, hence make them available for garbage collection.
Sometimes luck just strikes me, and that's what happened here: this approach extinguished all sudden crashes. The reporting instances got picked up by the garbage collector (I debugged that), but just a little bit later. Late enough for their finalization to run smoothly. So up to now I don't know the exact cause (as mentioned before, it must have been a timing problem - if reporting instances survive some seconds, they will not crash during finalization). We are still investigating it, and we will find a more suitable fix. But much more important: we shipped on time, and we made our customer happy. All end-user installations are working fine so far.
Do I like the current solution? No, it's a hack. But still it's 10.000 times better than shipping an unstable product. From a certain level of complexity on, all software products contain hacks. Just have a look at the Windows 2000 source (esp. the code comments) that were spread on P2P-networks some time ago. In an imperfect world, you sometimes have to settle with imperfect (but working) solutions for your problems.
Subscribe to:
Posts (Atom)