A while ago we integrated Microsoft Word as an embedded control inside one of our .NET applications. Most tutorials recommend the usage of AxSHDocVw.AxWebBrowser (available from the Visual Studio .NET WinForms designer toolbox), which allows simply to navigate to a file-URL pointing to a Word document. The problem is, AxWebBrowser is nothing else then the well known Internet Explorer webbrowser control, so its behavior depends on the client's internet settings. E.g. when "Confirm open after download" has been set, a file download dialog will appear when programmatically opening an Office document (even in case of a local file), and after confirming the document shows up in a new top-level Word or Excel window, not inside the webbrowser control's host (= your application). That's why we switched from AxWebBrowser to the DSOFramer ActiveX control provided by Microsoft, which doesn't have these restrictions.
Most of the time it's not only required to open Office documents but also to define/manipulate their content, e.g. by replacing form letter placeholders with user data. This can be done by applying Word's COM API. It's a good idea not to let Visual Studio generate COM Interop Assemblies on-the-fly (this generally happens when adding references to COM libraries), but to use Primary Interop Assemblies for Office. Those PIAs can then be redistributed together with the application itself. Note that there are different PIAs for different Office versions, e.g. Office XP and Office 2003. Using Office 2003 features on a client which only got Office XP installed will lead to QueryInterface failures. There are two ways to solve this: (A) develop against the lowest common denominator (e.g. Office XP) or (B) build two Office integration modules with similar functionality, but one of them compiled against Office XP PIAs, and the other one against Office 2003 PIAs. It can then be decided at runtime which of those assemblies to apply, depending on which Office version is available on the client. Hence it's possible to take advantage of Office 2003 features on clients with Office 2003 installed, without breaking Office XP clients. Office 2007 is not out yet, but I suppose the same will be the case there as well.
Follow-Ups:

Saturday, December 30, 2006
Thursday, December 28, 2006
Introduction To The Vanilla Data Access Layer For .NET (Part 2)
Vanilla DAL requires a configuration XML-file for each database to be accessed. The configuration schema definition (XSD) makes it easy to let a tool XML-tools auto-generate the basic element structure:
The sample application comes with the following configuration file.
The configuration file basically tells Vanilla which SQL-statements are available for execution. Every SQL-statement can be logged to stdout by setting the <logsql>-element to true.
Additionally Vanilla supports a simple Dataset-to-DB mapping based on ADO.NET Datasets, with no need to hand-code any SQL at all.
Typically the configuration-file will be compiled into the client's assembly. The ADO.NET connection string can either be specified at runtime (see below), or hard-wired inside the configuration file.
The complete Vanilla DAL API is based on the so called IDBAccessor interface. A tangible IDBAccessor implementation is created by the VanillaFactory at startup time:
Note: SqlServer 2005 Express Edition will install a server instance named (local)\sqlexpress by default.
IDBAccessor is an interface that every database-specific implementation has to support. Working against this interface, the client will never be contaminated with database-specific code. When connecting to another database, all that is required is another configuration file. Multiple configurations can be applied at the same time, simply by instantiating several IDBAccessors.
This is IDBAccessor's current interface (may be subject to change):
At this point Vanilla is ready to go and may execute its first command (which has been declared in the configuration file - see CustomersByCityAndMinOrderCount):
The Datatable is now populated with the query's result.
Alternatively, Vanilla DAL can create select-, insert-, update- and delete-statements on-the-fly in case of a 1:1 mapping between Datatable and database. All that needs to be passed in is a Datatable, which will be filled in case of a select, resp. is supposed to hold data for inserts, updates and deletes:
The advantage of this approach lies in the fact changes of the underlying database schema do not necessarily require manual SQL code adaptation.
Additionally the FillParameter.SchemaHandling property can be applied to define whether the current Datatable schema should be updated by the underlying database schema. By default all columns supported by the Datatable will be fetched from the database (but not more). If there are no Datatable columns, they will be created during runtime. In this case every database column will result in a corresponding column in the Datatable.
Next we will do some in-memory data manipulation, and then update the database accordingly:
RefreshAfterUpdate = true tells Vanilla to issue another select command after the update, which is helpful in case database triggers change data during the process of inserting or updateing, or similar. Auto-increment values set by the database are loaded back to the Dataset automatically.
updateParameter.Locking = UpdateParameter.LockingType.Optimistic will ensure that only those rows are updated which have not been manipulated by someone else in the meantime. Otherwise a VanillaConcurrencyException will be thrown.
At any time, custom SQL code can be executed as well:
To sum up, here is complete sample application:
Part 1 of the Vanilla DAL article series can be found here.
<?xml version="1.0" encoding="utf-8"?>
<xs:schema elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="Config" nillable="true" type="Configuration" />
<xs:complexType name="Configuration">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="1" name="ConnectionString" type="xs:string" />
<xs:element minOccurs="1" maxOccurs="1" name="DatabaseType" type="ConfigDatabaseType" />
<xs:element minOccurs="0" maxOccurs="1" name="LogSql" type="xs:boolean" />
<xs:element minOccurs="0" maxOccurs="1" name="Statements" type="ArrayOfConfigStatement" />
</xs:sequence>
</xs:complexType>
<xs:simpleType name="ConfigDatabaseType">
<xs:restriction base="xs:string">
<xs:enumeration value="Undefined" />
<xs:enumeration value="SQLServer" />
<xs:enumeration value="Oracle" />
<xs:enumeration value="OLEDB" />
</xs:restriction>
</xs:simpleType>
<xs:complexType name="ArrayOfConfigStatement">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="unbounded" name="Statement" nillable="true" type="ConfigStatement" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="ConfigStatement">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="1" name="ID" type="xs:string" />
<xs:element minOccurs="1" maxOccurs="1" name="StatementType" type="ConfigStatementType" />
<xs:element minOccurs="0" maxOccurs="1" name="Code" type="xs:string" />
<xs:element minOccurs="0" maxOccurs="1" name="Parameters" type="ArrayOfConfigParameter" />
</xs:sequence>
</xs:complexType>
<xs:simpleType name="ConfigStatementType">
<xs:restriction base="xs:string">
<xs:enumeration value="Undefined" />
<xs:enumeration value="Text" />
<xs:enumeration value="StoredProcedure" />
</xs:restriction>
</xs:simpleType>
<xs:complexType name="ArrayOfConfigParameter">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="unbounded" name="Parameter" nillable="true" type="ConfigParameter" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="ConfigParameter">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="1" name="Name" type="xs:string" />
<xs:element minOccurs="1" maxOccurs="1" name="Type" type="ConfigParameterType" />
</xs:sequence>
</xs:complexType>
<xs:simpleType name="ConfigParameterType">
<xs:restriction base="xs:string">
<xs:enumeration value="Undefined" />
<xs:enumeration value="Byte" />
<xs:enumeration value="Int16" />
<xs:enumeration value="Int32" />
<xs:enumeration value="Int64" />
<xs:enumeration value="Double" />
<xs:enumeration value="Boolean" />
<xs:enumeration value="DateTime" />
<xs:enumeration value="String" />
<xs:enumeration value="Guid" />
<xs:enumeration value="Decimal" />
<xs:enumeration value="ByteArray" />
</xs:restriction>
</xs:simpleType>
</xs:schema>
The sample application comes with the following configuration file.
<?xml version="1.0" encoding="UTF-8"?>
<!-- if this is a visual studio embedded resource, recompile project on each change -->
<Config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<DatabaseType>SQLServer</DatabaseType>
<LogSql>true</LogSql>
<!-- Oracle: <DatabaseType>Oracle</DatabaseType> -->
<!-- OLEDB: <DatabaseType>OLEDB</DatabaseType> -->
<Statements>
<Statement>
<StatementType>StoredProcedure</StatementType>
<ID>CustOrderHist</ID>
<Code>
<![CDATA[CustOrderHist]]>
</Code>
<Parameters>
<Parameter>
<Name>customerid</Name>
<Type>String</Type>
</Parameter>
</Parameters>
</Statement>
<Statement>
<StatementType>Text</StatementType>
<ID>CustomersByCityAndMinOrderCount</ID>
<Code><![CDATA[
select *
from customers
where city = @city and
(select count(*) from orders
where orders.customerid = customers.customerid) >=
@minordercount
]]></Code>
<!-- Oracle:
<Code><![CDATA[
select *
from customers
where city = :city and
(select count(*) from orders where orders.customerid =
customers.customerid) >= :minordercount
]]></Code>
-->
<!-- OLEDB:
<Code><![CDATA[
select *
from customers
where city = ? and
(select count(*) from orders where orders.customerid =
customers.customerid) >= ?
]]></Code>
-->
<Parameters>
<Parameter>
<Name>city</Name>
<Type>String</Type>
</Parameter>
<Parameter>
<Name>minordercount</Name>
<Type>Int32</Type>
</Parameter>
</Parameters>
</Statement>
<Statement>
<StatementType>Text</StatementType>
<ID>CustomerCount</ID>
<Code>
<![CDATA[
select count(*)
from customers
]]>
</Code>
<Parameters>
</Parameters>
</Statement>
<Statement>
<StatementType>Text</StatementType>
<ID>DeleteTestCustomers</ID>
<Code>
<![CDATA[
delete
from customers
where companyname like 'Test%'
]]>
</Code>
<Parameters>
</Parameters>
</Statement>
</Statements>
</Config>
The configuration file basically tells Vanilla which SQL-statements are available for execution. Every SQL-statement can be logged to stdout by setting the <logsql>-element to true.
Additionally Vanilla supports a simple Dataset-to-DB mapping based on ADO.NET Datasets, with no need to hand-code any SQL at all.
Typically the configuration-file will be compiled into the client's assembly. The ADO.NET connection string can either be specified at runtime (see below), or hard-wired inside the configuration file.
The complete Vanilla DAL API is based on the so called IDBAccessor interface. A tangible IDBAccessor implementation is created by the VanillaFactory at startup time:
Assembly.GetExecutingAssembly().GetManifestResourceStream(
"VanillaTest.config.xml"),
"Data Source=(local);Initial Catalog=Northwind;
Integrated Security=True");
IDBAccessor accessor = VanillaFactory.CreateDBAccessor(config);
Note: SqlServer 2005 Express Edition will install a server instance named (local)\sqlexpress by default.
IDBAccessor is an interface that every database-specific implementation has to support. Working against this interface, the client will never be contaminated with database-specific code. When connecting to another database, all that is required is another configuration file. Multiple configurations can be applied at the same time, simply by instantiating several IDBAccessors.
This is IDBAccessor's current interface (may be subject to change):
public interface IDBAccessor {
IDbCommand CreateCommand(CommandParameter param);
IDbConnection CreateConnection();
IDbDataAdapter CreateDataAdapter();
void Fill(FillParameter param);
int Update(UpdateParameter param);
int ExecuteNonQuery(NonQueryParameter param);
object ExecuteScalar(ScalarParameter param);
void ExecuteTransaction(TransactionTaskList list);
}
At this point Vanilla is ready to go and may execute its first command (which has been declared in the configuration file - see CustomersByCityAndMinOrderCount):
NorthwindDataset northwindDataset = new NorthwindDataset();
accessor.Fill(new FillParameter(
northwindDataset.Customers,
new Statement("CustomersByCityAndMinOrderCount"),
new ParameterList(
new Parameter("city", "London"),
new Parameter("minordercount", 2)))
);
The Datatable is now populated with the query's result.
Alternatively, Vanilla DAL can create select-, insert-, update- and delete-statements on-the-fly in case of a 1:1 mapping between Datatable and database. All that needs to be passed in is a Datatable, which will be filled in case of a select, resp. is supposed to hold data for inserts, updates and deletes:
northwindDataset.Customers.Clear();
accessor.Fill(new FillParameter(northwindDataset.Customers));
The advantage of this approach lies in the fact changes of the underlying database schema do not necessarily require manual SQL code adaptation.
Additionally the FillParameter.SchemaHandling property can be applied to define whether the current Datatable schema should be updated by the underlying database schema. By default all columns supported by the Datatable will be fetched from the database (but not more). If there are no Datatable columns, they will be created during runtime. In this case every database column will result in a corresponding column in the Datatable.
Next we will do some in-memory data manipulation, and then update the database accordingly:
northwindDataset.Customers.Clear();
accessor.Fill(new FillParameter(northwindDataset.Customers));
foreach (NorthwindDataset.CustomersRow cust1 in
northwindDataset.Customers) {
cust1.City = "New York";
}
UpdateParameter upd1 =
new UpdateParameter(northwindDataset.Customers);
upd1.RefreshAfterUpdate = true;
upd1.Locking = UpdateParameter.LockingType.Optimistic;
accessor.Update(upd1);
RefreshAfterUpdate = true tells Vanilla to issue another select command after the update, which is helpful in case database triggers change data during the process of inserting or updateing, or similar. Auto-increment values set by the database are loaded back to the Dataset automatically.
updateParameter.Locking = UpdateParameter.LockingType.Optimistic will ensure that only those rows are updated which have not been manipulated by someone else in the meantime. Otherwise a VanillaConcurrencyException will be thrown.
At any time, custom SQL code can be executed as well:
Datatable table3 = new Datatable();
ConfigStatement s = new ConfigStatement(ConfigStatementType.Text,
"select * from customers");
accessor.Fill(new FillParameter(
table3,
new Statement(s)));
To sum up, here is complete sample application:
try {
// load db-specific config and instantiate accessor
VanillaConfig config = VanillaConfig.CreateConfig(
Assembly.GetExecutingAssembly().GetManifestResourceStream
("VanillaTest.config.xml"),
"Data Source=(local);Initial Catalog=Northwind;Integrated Security=True");
// SqlServer: "Data Source=(local);Initial Catalog=Northwind;Integrated Security=True"
// SqlServer Express: "Data Source=(local)\\SQLEXPRESS;Initial Catalog=Northwind;Integrated Security=True"
// Oracle: "Server=localhost;User ID=scott;Password=tiger"
// Access: "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\\Program Files\\Microsoft Office\\OFFICE11\\SAMPLES\\Northwind.mdb"
IDBAccessor accessor = VanillaFactory.CreateDBAccessor(config);
// custom statement
NorthwindDataset northwindDataset = new NorthwindDataset();
accessor.Fill(new FillParameter(
northwindDataset.Customers,
new Statement("CustomersByCityAndMinOrderCount"),
new ParameterList(
new Parameter("city", "London"),
new Parameter("minordercount", 2)))
);
// insert data
NorthwindDataset.CustomersRow custIns = northwindDataset.Customers.NewCustomersRow();
custIns.CustomerID = "Foo";
custIns.CompanyName = "Foo";
custIns.City = "New York";
northwindDataset.Customers.AddCustomersRow(custIns);
try
{
accessor.Update(new UpdateParameter(northwindDataset.Customers));
}
catch (VanillaException e)
{
Console.WriteLine(e.Message);
}
// insert and delete data
NorthwindDataset.CustomersRow custDel = northwindDataset.Customers.NewCustomersRow();
custDel.CustomerID = "Foo2";
custDel.CompanyName = "Foo2";
custDel.City = "New York";
northwindDataset.Customers.AddCustomersRow(custDel);
try
{
accessor.Update(new UpdateParameter(northwindDataset.Customers));
custDel.Delete();
accessor.Update(new UpdateParameter(northwindDataset.Customers));
}
catch (VanillaException e)
{
Console.WriteLine(e.Message);
}
// custom statement preprocessed (due to user request)
northwindDataset.Customers.Clear();
ConfigStatement stmt = config.GetStatement("CustomersByCityAndMinOrderCount");
ConfigStatement stmt2 =
new ConfigStatement(stmt.StatementType, stmt.Code + " and 1=1", stmt.Parameters);
accessor.Fill(new FillParameter(
northwindDataset.Customers,
new Statement(stmt2),
new ParameterList(
new Parameter("city", "London"),
new Parameter("minordercount", 2)))
);
// generic statement, this means no sql statement is required (as dataset maps 1:1 to db)
// dataset without schema will receive schema information from db (all columns)
// FillParameter.SchemaHandling allows to apply different schema strategies
DataTable table1 = new DataTable();
accessor.Fill(new FillParameter(table1, "Customers"));
// invoke stored procedure
DataTable table2 = new DataTable();
accessor.Fill(new FillParameter(
table2,
new Statement("CustOrderHist"),
new ParameterList(new Parameter("customerid", "Foo"))));
// hardcoded custom statement (due to user request)
DataTable table3 = new DataTable();
ConfigStatement s = new ConfigStatement(ConfigStatementType.Text, "select * from customers");
accessor.Fill(new FillParameter(
table3,
new Statement(s)));
// simulate a concurrency issue
// fetch the same data twice
northwindDataset.Customers.Clear();
// sql code will be generated on-the-fly, based on the columsn defined in this typed dataset
accessor.Fill(new FillParameter(northwindDataset.Customers, new ParameterList(new Parameter("CustomerID", "Foo"))));
NorthwindDataset northwindDataset2 = new NorthwindDataset();
accessor.Fill(new FillParameter(northwindDataset2.Customers, new ParameterList(new Parameter("CustomerID", "Foo"))));
// write some changes back to db
foreach (NorthwindDataset.CustomersRow cust1 in northwindDataset.Customers)
{
cust1.City = "Paris";
}
UpdateParameter upd1 = new UpdateParameter(northwindDataset.Customers);
upd1.RefreshAfterUpdate = true;
upd1.Locking = UpdateParameter.LockingType.Optimistic;
accessor.Update(upd1);
// try to write some other changes back to db which are now based on wrong original values => concurrency excpetion
foreach (NorthwindDataset.CustomersRow cust in northwindDataset2.Customers) {
cust.City = "Berlin";
}
UpdateParameter upd2 = new UpdateParameter(northwindDataset2.Customers);
upd2.RefreshAfterUpdate = true;
upd2.Locking = UpdateParameter.LockingType.Optimistic;
try {
accessor.Update(upd2);
}
catch (VanillaConcurrencyException e) {
Console.WriteLine(e.Message);
}
// transaction example
northwindDataset.Customers.Clear();
NorthwindDataset.CustomersRow cust2 =
northwindDataset.Customers.NewCustomersRow();
cust2.CustomerID = "TEST1";
cust2.CompanyName = "Tester 1";
northwindDataset.Customers.AddCustomersRow(cust2);
TransactionTaskList list = new TransactionTaskList(
// generic update custom statement
new UpdateTransactionTask(
new UpdateParameter(northwindDataset.Customers)),
// custom statement
new ExecuteNonQueryTransactionTask(
new NonQueryParameter(new Statement("DeleteTestCustomers")))
);
accessor.ExecuteTransaction(list);
Console.WriteLine("VanillaTest completed successfully");
}
catch (VanillaException e) {
Console.WriteLine(e.Message);
}
Console.Write("Press to continue...");
Console.Read();
}
Part 1 of the Vanilla DAL article series can be found here.
Monday, December 11, 2006
Introduction To The Vanilla Data Access Layer For .NET (Part 1)
When I attended a one-week introductory course to .NET back in 2002, the instructor first showed several of Visual Studio's RAD features. He dropped a database table onto a WinForm, which automatically created a typed DataSet plus a ready-to-go DataAdapter, including SQL code. After binding the DataSet to a grid and invoking the DataAdapter's fill-method (one line of hand-written code) the application loaded and displayed database content. My guess is that nearly every .NET developer has seen similar examples.
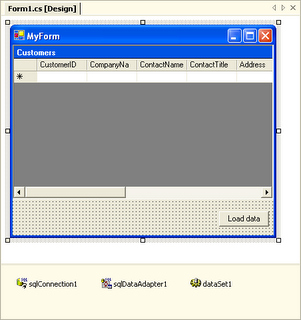 Picture 1: Mixing UI and Data Access Code in Visual Studio .NET
Picture 1: Mixing UI and Data Access Code in Visual Studio .NET
Of course most people will immediately note some drawbacks in this approach. For example, it is not a good idea to have SQL code and database connection strings cluttered all over WinForms or ASP.NET pages. "OK", the .NET instructor will reply at this point, "then don't drop it on a form, drop it on a .NET component class. Make the connection string a dynamic property and bind it to a value in a .config file."
Fair enough. And as a side note I should mention that Visual Studio 2005 has somewhat improved here as well. It won't produce SQL code inside Windows forms any more. Visual Studio 2005 manages project-wide datasources, and places SQL code in so called TableAdapters, which are coupled with the underlying typed DataSet (actually the TableAdapter's code resides in a partial DataSet class file). Whether this is a good idea or not remains questionable.
What has not changed in Visual Studio 2005 is how the SQL query builder works. Once again it looks like a nice feature at first sight, at least if all you want is some straight-forward DataSet-to-Table mapping. In general, query builder is used for editing SQL code embedded in .NET Components. Based on database schema information, it can also auto-generate select-, insert-, update- and delete-statements. Here we can see query builder in action:
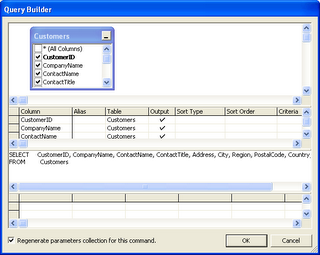 Picture 2: Visual Studio .NET Query Builder
Picture 2: Visual Studio .NET Query Builder
When a DataAdapter has been placed onto a Component's tray, query builder is the only way how to edit the SQL code attached to the DataAdapter's commands, as the SQL code format was certainly not designed for human readability:
 Picture 3: Resulting SQL Code
Picture 3: Resulting SQL Code
It turns out that query builder might not be everybody's tool of choice (maybe with the exception of people with a background in Microsoft Access). Every additional (or removed) database attribute implies code re-generation or manual adaptation. There is no syntax highlighting, no testing capability, and to make things worse, query builder even tries to optimize logical expressions. There are scenarios when query builder definitely changes statement semantics.
ADO.NET is also missing support for database independence. Unlike JDBC and ODBC, which offer completely consistent APIs across all database systems and either are bound to a certain SQL standard or include some semantic extensions in order to address different SQL flavors, ADO.NET providers work in a very vendor-specific manner. While it is true that there exist interface definitions which each provider has to implement (e.g. System.Data.IDbConnection), those interfaces just represent a subset of overall functionality. It should be noted that ADO.NET provider model has improved with .NET 2.0 though.
Arguably there is always the alternative of hand-coding whatever data access feature or convenience function might be missing. But this implies that many people will end up implementing the same things over and over again (e.g. providing a storage system for SQL code, creating parameter-collections, instantiating DataAdapters, commands and connections, opening and closing connections, handling exceptions, managing transactions, encapsulating database-specifics, etc). While there are third party libraries available covering some of these areas many of those products either enforce a completely different programming model and/or involve a steep learning curve. So this is where the Vanilla Data Access Layer for .NET comes in.
Vanilla DAL is a framework for accessing relational databases with ADO.NET. It avoids the problems that RAD-style programming tends to impose, and at the same time helps improving developer productivity.
Features include:
Part 2 of the Vanilla DAL article series can be found here.
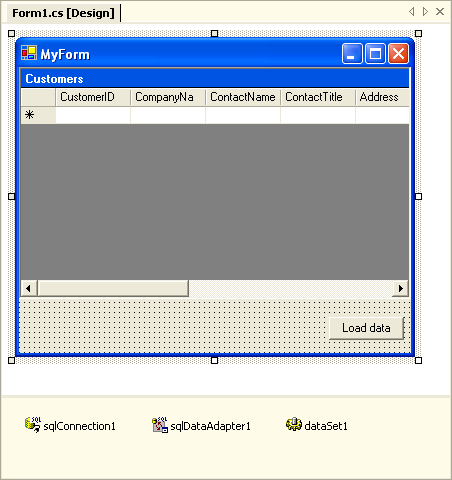 Picture 1: Mixing UI and Data Access Code in Visual Studio .NET
Picture 1: Mixing UI and Data Access Code in Visual Studio .NETOf course most people will immediately note some drawbacks in this approach. For example, it is not a good idea to have SQL code and database connection strings cluttered all over WinForms or ASP.NET pages. "OK", the .NET instructor will reply at this point, "then don't drop it on a form, drop it on a .NET component class. Make the connection string a dynamic property and bind it to a value in a .config file."
Fair enough. And as a side note I should mention that Visual Studio 2005 has somewhat improved here as well. It won't produce SQL code inside Windows forms any more. Visual Studio 2005 manages project-wide datasources, and places SQL code in so called TableAdapters, which are coupled with the underlying typed DataSet (actually the TableAdapter's code resides in a partial DataSet class file). Whether this is a good idea or not remains questionable.
What has not changed in Visual Studio 2005 is how the SQL query builder works. Once again it looks like a nice feature at first sight, at least if all you want is some straight-forward DataSet-to-Table mapping. In general, query builder is used for editing SQL code embedded in .NET Components. Based on database schema information, it can also auto-generate select-, insert-, update- and delete-statements. Here we can see query builder in action:
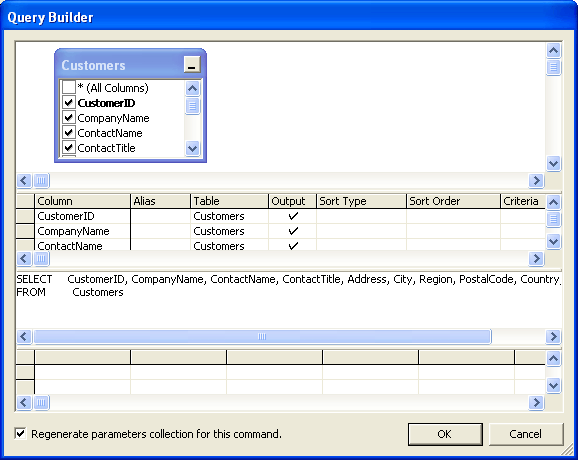 Picture 2: Visual Studio .NET Query Builder
Picture 2: Visual Studio .NET Query BuilderWhen a DataAdapter has been placed onto a Component's tray, query builder is the only way how to edit the SQL code attached to the DataAdapter's commands, as the SQL code format was certainly not designed for human readability:
 Picture 3: Resulting SQL Code
Picture 3: Resulting SQL CodeIt turns out that query builder might not be everybody's tool of choice (maybe with the exception of people with a background in Microsoft Access). Every additional (or removed) database attribute implies code re-generation or manual adaptation. There is no syntax highlighting, no testing capability, and to make things worse, query builder even tries to optimize logical expressions. There are scenarios when query builder definitely changes statement semantics.
ADO.NET is also missing support for database independence. Unlike JDBC and ODBC, which offer completely consistent APIs across all database systems and either are bound to a certain SQL standard or include some semantic extensions in order to address different SQL flavors, ADO.NET providers work in a very vendor-specific manner. While it is true that there exist interface definitions which each provider has to implement (e.g. System.Data.IDbConnection), those interfaces just represent a subset of overall functionality. It should be noted that ADO.NET provider model has improved with .NET 2.0 though.
Arguably there is always the alternative of hand-coding whatever data access feature or convenience function might be missing. But this implies that many people will end up implementing the same things over and over again (e.g. providing a storage system for SQL code, creating parameter-collections, instantiating DataAdapters, commands and connections, opening and closing connections, handling exceptions, managing transactions, encapsulating database-specifics, etc). While there are third party libraries available covering some of these areas many of those products either enforce a completely different programming model and/or involve a steep learning curve. So this is where the Vanilla Data Access Layer for .NET comes in.
Vanilla DAL is a framework for accessing relational databases with ADO.NET. It avoids the problems that RAD-style programming tends to impose, and at the same time helps improving developer productivity.
Features include:
- SQL statement externalization in XML-files
- Wrapping database-specific code, hence laying the groundwork for database independence
- SQL code generation based on DB or Dataset schema information
- Automatic transaction handling (no need to repeat the same begin transaction-try-commit-catch-rollback sequence over and over again) and transaction propagation on data access
- Optimistic locking without any handwritten code
- SQL statement tracing
- Several convenience functions of common interest
Part 2 of the Vanilla DAL article series can be found here.
Thursday, December 07, 2006
When Web Design Goes Wrong
Great article that pretty much sums up the various ways of how web design can go wrong. Also includes some funny videos of website visitors losing their nerve.


Friday, December 01, 2006
Hibernate Reverse Engineering And SqlServer Identity Columns
I might be wrong on this, but it seems to me that the latest Hibernate Tools produce wrong mapping configuration for SqlServer identity (aka auto-increment) columns. While I'd expect
what I get is
which leads to a database error at runtime as Hibernate tries to create the primary key value, unless I change the setting back to "identity". I use Microsoft's latest JDBC driver. No big deal though, because Hibernate allows to define the reverse engineering strategy in great detail, so this behavior can easily be overridden. It's also quite likely I am doing something wrong to begin with, because I haven't found any existing bug report on this issue.
More Hibernate postings:
<generator class="identity" />what I get is
<generator class="assigned" />which leads to a database error at runtime as Hibernate tries to create the primary key value, unless I change the setting back to "identity". I use Microsoft's latest JDBC driver. No big deal though, because Hibernate allows to define the reverse engineering strategy in great detail, so this behavior can easily be overridden. It's also quite likely I am doing something wrong to begin with, because I haven't found any existing bug report on this issue.
More Hibernate postings:
Subscribe to:
Comments (Atom)