
 Picture 1: Mixing UI and Data Access Code in Visual Studio .NET
Picture 1: Mixing UI and Data Access Code in Visual Studio .NETOf course most people will immediately note some drawbacks in this approach. For example, it is not a good idea to have SQL code and database connection strings cluttered all over WinForms or ASP.NET pages. "OK", the .NET instructor will reply at this point, "then don't drop it on a form, drop it on a .NET component class. Make the connection string a dynamic property and bind it to a value in a .config file."
Fair enough. And as a side note I should mention that Visual Studio 2005 has somewhat improved here as well. It won't produce SQL code inside Windows forms any more. Visual Studio 2005 manages project-wide datasources, and places SQL code in so called TableAdapters, which are coupled with the underlying typed DataSet (actually the TableAdapter's code resides in a partial DataSet class file). Whether this is a good idea or not remains questionable.
What has not changed in Visual Studio 2005 is how the SQL query builder works. Once again it looks like a nice feature at first sight, at least if all you want is some straight-forward DataSet-to-Table mapping. In general, query builder is used for editing SQL code embedded in .NET Components. Based on database schema information, it can also auto-generate select-, insert-, update- and delete-statements. Here we can see query builder in action:
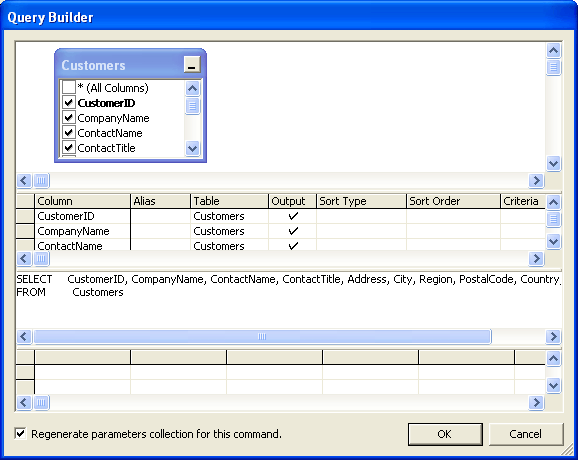 Picture 2: Visual Studio .NET Query Builder
Picture 2: Visual Studio .NET Query BuilderWhen a DataAdapter has been placed onto a Component's tray, query builder is the only way how to edit the SQL code attached to the DataAdapter's commands, as the SQL code format was certainly not designed for human readability:
 Picture 3: Resulting SQL Code
Picture 3: Resulting SQL CodeIt turns out that query builder might not be everybody's tool of choice (maybe with the exception of people with a background in Microsoft Access). Every additional (or removed) database attribute implies code re-generation or manual adaptation. There is no syntax highlighting, no testing capability, and to make things worse, query builder even tries to optimize logical expressions. There are scenarios when query builder definitely changes statement semantics.
ADO.NET is also missing support for database independence. Unlike JDBC and ODBC, which offer completely consistent APIs across all database systems and either are bound to a certain SQL standard or include some semantic extensions in order to address different SQL flavors, ADO.NET providers work in a very vendor-specific manner. While it is true that there exist interface definitions which each provider has to implement (e.g. System.Data.IDbConnection), those interfaces just represent a subset of overall functionality. It should be noted that ADO.NET provider model has improved with .NET 2.0 though.
Arguably there is always the alternative of hand-coding whatever data access feature or convenience function might be missing. But this implies that many people will end up implementing the same things over and over again (e.g. providing a storage system for SQL code, creating parameter-collections, instantiating DataAdapters, commands and connections, opening and closing connections, handling exceptions, managing transactions, encapsulating database-specifics, etc). While there are third party libraries available covering some of these areas many of those products either enforce a completely different programming model and/or involve a steep learning curve. So this is where the Vanilla Data Access Layer for .NET comes in.
Vanilla DAL is a framework for accessing relational databases with ADO.NET. It avoids the problems that RAD-style programming tends to impose, and at the same time helps improving developer productivity.
Features include:
- SQL statement externalization in XML-files
- Wrapping database-specific code, hence laying the groundwork for database independence
- SQL code generation based on DB or Dataset schema information
- Automatic transaction handling (no need to repeat the same begin transaction-try-commit-catch-rollback sequence over and over again) and transaction propagation on data access
- Optimistic locking without any handwritten code
- SQL statement tracing
- Several convenience functions of common interest
Part 2 of the Vanilla DAL article series can be found here.