
Friday, October 29, 2004
Journey To The Past (4): The PC (1987)
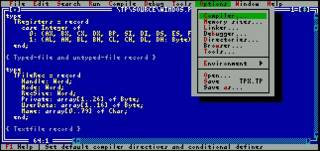
My school heavily invested into computer equipment, and bought brand new IBM-compatible PCs, that came with MS DOS 3.3. We started coding in Turbo Pascal, which was a fine environment for making my first steps in structured programming.

Thursday, October 28, 2004
Journey To The Past (3): Commodore 128 (1986-1988)
The first home computer I ever possessed was a Commodore 128D. Starting with C64 Basic, I used to write endless text-base adventure games (until I ran out of memory), which mainly consisted of a page of prints and a prompt asking the user to choose one option for his next move. Later, I discovered Simon's Basic, an enhancement of C64 basic, which allowed for graphical on-screen operations, and started to get to know C128 Basic. I also managed to get CP/M running (the first real operating system for micros) and Turbo Pascal for CP/M, so I could do computer science assignments at home.


Tuesday, October 26, 2004
Curious Perversions In Information Technology
"The Daily WTF" is a collection of really kinky code snipplets posted by unfortunate maintenance programmers. The level of these code samples ranges between "unbelievable" and "absolutely hilarious". I actually felt better after skim-reading those postings. I thought I had seen the bad and the ugly, but hey, there is even worse out there.
My personal favorites so far include:
So here is my own Top Ten List Of Programming Perversions. I have encountered them over the years. To stay fair, I am not going to post any code or other hints about their origin, so here is an anonymized version:
10. Declare it a Java List, but instantiate it as a LinkedList, then access all elements sequentially (from 0 to n - 1) by invoking List.get(int). Ehm - LinkedList, you know... a LINKED list? Here is what the doc says: Operations that index into the list will traverse the list from the begining or the end, whichever is closer to the specified index. Iterators, maybe?
9. Implement your own String.indexOf(String) in Java. Uhm, it does not work, and it does not perform. But hey, still better than Sun's library functions.
8. Draw a Windows GDI DIB (device-independent bitmap) by calculating each and every pixel's COLORREF and invoke SetPixel() on it. SetPixel also updates the screen synchronously. Yes, performance rocks - you can actually watch the painting process scanline by scanline. BitBlt(), anybody?
7. Write a RasterOp library, which - in its most-called function (SetAtom(), the function that is responsible for setting a pixel by applying a bit-mask resp. one or two bit-shifting operations) - checks for the current clipping rectangle and adjusts the blitting rectangle by creating some Rectangle objects and invoking several methods on those Rectangle objects. Ignore the fact that more or less all simple RasterOp's (like FillRect(), DrawLine() and the like) already define which region will be affected and offer a one-time possibility to adjust clipping and blitting. Instead do it repeatedly on each pixel drawn and create a performance penalty of about 5000%. Also prevent SetAtom() from being inlined by the compiler.
6. Custom ListBox control, programmed in C++. On every ListBox item's repaint event, create about ten (custom) string objects on the stack. Copy-assign senselessly to and from those strings (which all have the same character content), which leads to constant re-allocation of the strings' internal buffers. Score extra points by doing all of that on an embedded system. Really, a string's value type assignment-operator does work differently from the reference type assignment operator, which simply copies references? It might invoke all kind of other weird stuff, like malloc(), memcpy(), free() and the like? How should you have known that?
5. Use a Java obfuscator to scramble string constants, which are hardcoded and cluttered all over inner-most loop bodies (what about constants?). This implies de-obfuscation at runtime (including some fancy decryption-algorithm), each time the string is being accessed. Yes, it is used for self-implemented XML-parsing (see (2)) on megabytes of XML-streams.
4. Convert a byte-buffer to a string under C++/MFC: Instantiate one CString for each byte, write the byte to the CString's buffer, and concatenate this CString to another CString using the "+"-operator.
3. Build your own Object-Relational-Mapper, ignoring the fact that there are plenty of them freely available. Argue that this lowers the learning curve for programmers who don't know SQL (sure it make sense to employ programmers who don't know SQL in the first place). When your (actually SQL-capable) programmers complain that your ORM is missing a working query language, tell them to load a whole table's content into memory, and apply filters in-memory. Or: open a backdoor for SQL again (queries only). Let them define the mapping configuration in XML without providing any tool for automization or validation. Find out that your custom ORM just won't scale AFTER it has been installed on your customer's production environment. Finally conclude that you had preferred to shoot yourself in the foot instead of using Hibernate.
2. The self-implemented Java XML-Parser on a JDK 1.3 runtime (huh, there are dozens of JAXP-compliant, freely available XML-Parsers out there). Highly inefficient (about 100 times slower than Apache Xerces) and actually not-working (what are XML escape sequences again?).
1. Invent the One-Table-Database (yes, exactly what you are thinking of now...)
My personal favorites so far include:
- From the "It worked when I tested it" Department (Or: "Regular Expre-What?")
- Round() we go again
- If only Java supported XML... (I know a similar case - see below. Those guys implemented their own XML-Parser in Java. Maybe we are talking about the same vendor?)
- Not quite getting that Object-polymorphism thing...
- IsTrue()
- It seems my app is running a little slow...
- And I think I'll call it... "Referential Integrity"
- Can you think of a worse solution than this?
- You don't even need a stinkin' WHERE!
- Pointless Pointless Pointless Pointless Pointless Pointless Pointless
So here is my own Top Ten List Of Programming Perversions. I have encountered them over the years. To stay fair, I am not going to post any code or other hints about their origin, so here is an anonymized version:
10. Declare it a Java List, but instantiate it as a LinkedList, then access all elements sequentially (from 0 to n - 1) by invoking List.get(int). Ehm - LinkedList, you know... a LINKED list? Here is what the doc says: Operations that index into the list will traverse the list from the begining or the end, whichever is closer to the specified index. Iterators, maybe?
9. Implement your own String.indexOf(String) in Java. Uhm, it does not work, and it does not perform. But hey, still better than Sun's library functions.
8. Draw a Windows GDI DIB (device-independent bitmap) by calculating each and every pixel's COLORREF and invoke SetPixel() on it. SetPixel also updates the screen synchronously. Yes, performance rocks - you can actually watch the painting process scanline by scanline. BitBlt(), anybody?
7. Write a RasterOp library, which - in its most-called function (SetAtom(), the function that is responsible for setting a pixel by applying a bit-mask resp. one or two bit-shifting operations) - checks for the current clipping rectangle and adjusts the blitting rectangle by creating some Rectangle objects and invoking several methods on those Rectangle objects. Ignore the fact that more or less all simple RasterOp's (like FillRect(), DrawLine() and the like) already define which region will be affected and offer a one-time possibility to adjust clipping and blitting. Instead do it repeatedly on each pixel drawn and create a performance penalty of about 5000%. Also prevent SetAtom() from being inlined by the compiler.
6. Custom ListBox control, programmed in C++. On every ListBox item's repaint event, create about ten (custom) string objects on the stack. Copy-assign senselessly to and from those strings (which all have the same character content), which leads to constant re-allocation of the strings' internal buffers. Score extra points by doing all of that on an embedded system. Really, a string's value type assignment-operator does work differently from the reference type assignment operator, which simply copies references? It might invoke all kind of other weird stuff, like malloc(), memcpy(), free() and the like? How should you have known that?
5. Use a Java obfuscator to scramble string constants, which are hardcoded and cluttered all over inner-most loop bodies (what about constants?). This implies de-obfuscation at runtime (including some fancy decryption-algorithm), each time the string is being accessed. Yes, it is used for self-implemented XML-parsing (see (2)) on megabytes of XML-streams.
4. Convert a byte-buffer to a string under C++/MFC: Instantiate one CString for each byte, write the byte to the CString's buffer, and concatenate this CString to another CString using the "+"-operator.
3. Build your own Object-Relational-Mapper, ignoring the fact that there are plenty of them freely available. Argue that this lowers the learning curve for programmers who don't know SQL (sure it make sense to employ programmers who don't know SQL in the first place). When your (actually SQL-capable) programmers complain that your ORM is missing a working query language, tell them to load a whole table's content into memory, and apply filters in-memory. Or: open a backdoor for SQL again (queries only). Let them define the mapping configuration in XML without providing any tool for automization or validation. Find out that your custom ORM just won't scale AFTER it has been installed on your customer's production environment. Finally conclude that you had preferred to shoot yourself in the foot instead of using Hibernate.
2. The self-implemented Java XML-Parser on a JDK 1.3 runtime (huh, there are dozens of JAXP-compliant, freely available XML-Parsers out there). Highly inefficient (about 100 times slower than Apache Xerces) and actually not-working (what are XML escape sequences again?).
1. Invent the One-Table-Database (yes, exactly what you are thinking of now...)
Journey To The Past (2): Commodore CBM 8032 (1985-1986)
At high-school there was a broad variety of microcomputers, namely an Apple II for the chemistry lab (I didn't really like chemistry enough in order to sign in for advanced voluntary classes, so I never had the chance to access it), a Radio Shack TRS-80, and several Commodore CBMs. We used the CBM (an upgraded Commodore PET model) in computer science classes, where we learned about some more advanced topics, and solved problems like waiting queue simulations, or simple text-based, keyboard-controlled racing games.


Monday, October 25, 2004
Journey To The Past (1): Sinclair ZX-80 (1984)
My first programming experiments go back to the year 1984. A schoolmate of mine owned a Sinclair ZX-80, an early 8-bit microcomputer, that came with the famous Zilog Z80, 16K RAM, a rubber-like keyboard, and could be plugged into a TV set. I somehow managed to convince my friend to lend me his ZX-80 over summer holidays, and started writing my first lines of Basic. The storage system was a tape recorder, simply connected with audio cables.


1984
It has been twenty years since my first contact with computers. Time for a journey to the past. I have spent some time digging for old pictures and screenshots, and composed a mini-series of hardware- and software-technologies that I have worked with over the years.
You see, that's why 1984 was not going to be like George Orwell's "1984". OK, someone else actually said that. For me, it all started with a Sinclar ZX-80...
You see, that's why 1984 was not going to be like George Orwell's "1984". OK, someone else actually said that. For me, it all started with a Sinclar ZX-80...
From IEEE Spectrum
- If an apparently serious problem manifests itself, no solution is acceptable unless it is involved, expensive and time-consuming.
- Completion of any task within the allocated time and budget does not bring credit upon the performing personnel - it merely proves that the task was easier than expected.
- Failure to complete any task within the allocated time and budget proves the task was more difficult than expected and requires promotion for those in charge.
- Sufficient monies to do the job correctly the first time are usually not available; however, ample funds are much more easily obtained for repeated major redesigns.
A Luminary Is On My Side
I was reading Joel Spolsky's latest book last night, where I found another real gemstone: "Back to Basics", which shows some surprisingly (or probably not so surprisingly?) close analogies to what I tried to express just a short time ago. Joel Spolsky writes about performance issues on C strings, in particular the strcat() function, and concludes:
These are all things that require you to think about bytes, and they affect the big top-level decisions we make in all kinds of architecture and strategy. This is why my view of teaching is that first year CS students need to start at the basics, using C and building their way up from the CPU. I am actually physically disgusted that so many computer science programs think that Java is a good introductory language, because it's "easy" and you don't get confused with all that boring string/malloc stuff but you can learn cool OOP stuff which will make your big programs ever so modular. This is a pedagogical disaster waiting to happen.
Here is what I had to say some weeks ago:
The course curriculum here in Austria allows you to walk through a computer science degree without writing a single line of C or C++ (not to mention assembler).
[...]
What computer science professors tend to forget is that the opposite course is likely to happen as well to those graduates once they enter working life (those who have only applied Java or C#). There is more than Java and C# out there. And this "backward" paradigm shift is a much more difficult one. Appointing inexperienced Java programmers to a C++ or C project is a severe project risk.
It's a nice comfort to know that my opinion complies with the conclusions of a real software development celebrity. I admire Joel Spolsky's knowledge of the software industry's internal mode of operation, but the same is true for his excellent writing style. His writings are perceptive and entertaining at the same time.
In another article, "The Guerrilla Guide to Interviewing", Joel states:
Many "C programmers" just don't know how to make pointer arithmetic work. Now, ordinarily, I wouldn't reject a candidate just because he lacked a particular skill. However, I've discovered that understanding pointers in C is not a skill, it's an aptitude. In Freshman year CompSci, there are always about 200 kids at the beginning of the semester, all of whom wrote complex adventure games in BASIC for their Atari 800s when they were 4 years old. They are having a good ol'; time learning Pascal in college, until one day their professor introduces pointers, and suddenly, they don't get it. They just don't understand anything any more. 90% of the class goes off and becomes PoliSci majors, then they tell their friends that there weren't enough good looking members of the appropriate sex in their CompSci classes, that's why they switched. For some reason most people seem to be born without the part of the brain that understands pointers. This is an aptitude thing, not a skill thing – it requires a complex form of doubly-indirected thinking that some people just can't do.
<humor_mode>Java is for wimps. Real developer use C.</humor_mode>
But there is something very true in that. So much harm is done by people who just don't understand the underlyings of their code.
I have been quite lucky so far. Either I could choose my project team members (admitted, from a quite limited pool of candidates), or I happened to work in an environment with sufficiently qualified people anyway. But I know of many occasions when the opposite happened. The candidates cheated on their resume. Their presentation skills were good, so they obscured their technical incompetence - even to technical-savvy interviewers. Those interviewers just didn't dig deep enough. They were too busy presenting their company, talking 80% of the time. They really should just have asked the right questions instead. And they should have spent more time on listening carefully.
Joel is actually looking for Triple-A people only. That's kind of hard when you work in a corporate environment. I do not have any influence on the recruiting process itself, so there is no "Hire" or "No Hire" flag I could wave. In order to attract excellent people, I can only try to ensure a professional working environment within the corporate boundaries. Still, this is not what potential hires get to see when they go through the recruiting process.
But I did something else. I forwarded "The Guerrilla Guide to Interviewing" to the people in charge.
These are all things that require you to think about bytes, and they affect the big top-level decisions we make in all kinds of architecture and strategy. This is why my view of teaching is that first year CS students need to start at the basics, using C and building their way up from the CPU. I am actually physically disgusted that so many computer science programs think that Java is a good introductory language, because it's "easy" and you don't get confused with all that boring string/malloc stuff but you can learn cool OOP stuff which will make your big programs ever so modular. This is a pedagogical disaster waiting to happen.
Here is what I had to say some weeks ago:
The course curriculum here in Austria allows you to walk through a computer science degree without writing a single line of C or C++ (not to mention assembler).
[...]
What computer science professors tend to forget is that the opposite course is likely to happen as well to those graduates once they enter working life (those who have only applied Java or C#). There is more than Java and C# out there. And this "backward" paradigm shift is a much more difficult one. Appointing inexperienced Java programmers to a C++ or C project is a severe project risk.
It's a nice comfort to know that my opinion complies with the conclusions of a real software development celebrity. I admire Joel Spolsky's knowledge of the software industry's internal mode of operation, but the same is true for his excellent writing style. His writings are perceptive and entertaining at the same time.
In another article, "The Guerrilla Guide to Interviewing", Joel states:
Many "C programmers" just don't know how to make pointer arithmetic work. Now, ordinarily, I wouldn't reject a candidate just because he lacked a particular skill. However, I've discovered that understanding pointers in C is not a skill, it's an aptitude. In Freshman year CompSci, there are always about 200 kids at the beginning of the semester, all of whom wrote complex adventure games in BASIC for their Atari 800s when they were 4 years old. They are having a good ol'; time learning Pascal in college, until one day their professor introduces pointers, and suddenly, they don't get it. They just don't understand anything any more. 90% of the class goes off and becomes PoliSci majors, then they tell their friends that there weren't enough good looking members of the appropriate sex in their CompSci classes, that's why they switched. For some reason most people seem to be born without the part of the brain that understands pointers. This is an aptitude thing, not a skill thing – it requires a complex form of doubly-indirected thinking that some people just can't do.
<humor_mode>Java is for wimps. Real developer use C.</humor_mode>
But there is something very true in that. So much harm is done by people who just don't understand the underlyings of their code.
I have been quite lucky so far. Either I could choose my project team members (admitted, from a quite limited pool of candidates), or I happened to work in an environment with sufficiently qualified people anyway. But I know of many occasions when the opposite happened. The candidates cheated on their resume. Their presentation skills were good, so they obscured their technical incompetence - even to technical-savvy interviewers. Those interviewers just didn't dig deep enough. They were too busy presenting their company, talking 80% of the time. They really should just have asked the right questions instead. And they should have spent more time on listening carefully.
Joel is actually looking for Triple-A people only. That's kind of hard when you work in a corporate environment. I do not have any influence on the recruiting process itself, so there is no "Hire" or "No Hire" flag I could wave. In order to attract excellent people, I can only try to ensure a professional working environment within the corporate boundaries. Still, this is not what potential hires get to see when they go through the recruiting process.
But I did something else. I forwarded "The Guerrilla Guide to Interviewing" to the people in charge.
Wednesday, October 20, 2004
The StringBuffer Myth
Charles Miller writes about his assessment of StringBuffer usage in Java:
One of my pet Java peeves is that some people religiously avoid the String concatenation operators, + and +=, because they are less efficient than the alternatives.
The theory goes like this. Strings are immutable. Thus, when you are concatenating "n" strings together, there must be "n - 1" intermediate String objects created in the process (including the final, complete String). Thus, to avoid dumping a bunch of unwanted String objects onto the garbage-collector, you should use the StringBuffer object instead.
So, by this theory,
For as long as I have been using Java, this has not been true. If you look at StringBuffer handling, you'll see the bytecodes that a Java compiler actually produces in those two cases. In most simple string-concatenation cases, the compiler will automatically convert a series of operations on Strings into a series of StringBuffer operations, and then pop the result back into a String.
The only time you need to switch to an explicit StringBuffer is in more complex cases, for example if the concatenation is occurring within a loop (see StringBuffer handling in loops).
Charles compares those to approaches:
VS.
As Charles points out correctly, the Java compiler internally replaces the string concatenation operators by a StringBuffer, which is converted back to a String at the end. This looks like the same result, as when using StringBuffer directly.
But the Java bytecode, that Charles analyzed in detail, only tells half of the story. What he did not take a closer look on was what happens inside the call to the StringBuffer constructor, which the compiler inserted. And that's where the real performance vulnerability strikes hard:
The constructor only allocates a buffer for holding the original String plus 16 characters. Not more than that. In addition, StringBuffer.append() only expands the StringBuffer's capacity to fit for the next String appended:
That means constant re-allocation on each consecutive call to StringBuffer.append().
You - the programmer - know better than that. You might know exactly how big the buffer is going to be in its final state - or if you don't know the exact number, you may at least apply a decent approximation. You can then construct your StringBuffer like this:
No constant reallocation necessary, that means better performance and less work for the garbage collector. And that's where the real benefit lies in when applying StringBuffer instead of String concatenation operators.
One of my pet Java peeves is that some people religiously avoid the String concatenation operators, + and +=, because they are less efficient than the alternatives.
The theory goes like this. Strings are immutable. Thus, when you are concatenating "n" strings together, there must be "n - 1" intermediate String objects created in the process (including the final, complete String). Thus, to avoid dumping a bunch of unwanted String objects onto the garbage-collector, you should use the StringBuffer object instead.
So, by this theory,
String a = b + c + d; is bad code, while String a = new StringBuffer(b).append(c).append(d).toString() is good code, despite the fact that the former is about a thousand times more readable than the latter.
For as long as I have been using Java, this has not been true. If you look at StringBuffer handling, you'll see the bytecodes that a Java compiler actually produces in those two cases. In most simple string-concatenation cases, the compiler will automatically convert a series of operations on Strings into a series of StringBuffer operations, and then pop the result back into a String.
The only time you need to switch to an explicit StringBuffer is in more complex cases, for example if the concatenation is occurring within a loop (see StringBuffer handling in loops).
Charles compares those to approaches:
return a + b + c;
VS.
StringBuffer s = new StringBuffer(a);
s.append(b);
s.append(c);
return s.toString();
As Charles points out correctly, the Java compiler internally replaces the string concatenation operators by a StringBuffer, which is converted back to a String at the end. This looks like the same result, as when using StringBuffer directly.
But the Java bytecode, that Charles analyzed in detail, only tells half of the story. What he did not take a closer look on was what happens inside the call to the StringBuffer constructor, which the compiler inserted. And that's where the real performance vulnerability strikes hard:
public StringBuffer(String str) {
this(str.length() + 16);
append(str);
}
The constructor only allocates a buffer for holding the original String plus 16 characters. Not more than that. In addition, StringBuffer.append() only expands the StringBuffer's capacity to fit for the next String appended:
public synchronized StringBuffer append(String str) {
if (str == null) {
str = String.valueOf(str);
}
int len = str.length();
int newcount = count + len;
if (newcount > value.length)
expandCapacity(newcount);
str.getChars(0, len, value, count);
count = newcount;
return this;
}
That means constant re-allocation on each consecutive call to StringBuffer.append().
You - the programmer - know better than that. You might know exactly how big the buffer is going to be in its final state - or if you don't know the exact number, you may at least apply a decent approximation. You can then construct your StringBuffer like this:
return new StringBuffer(
a.length() + b.length() + c.length()).
append(a).append(b).append(c).toString();
No constant reallocation necessary, that means better performance and less work for the garbage collector. And that's where the real benefit lies in when applying StringBuffer instead of String concatenation operators.
Monday, October 18, 2004
Exceptional C++
I am currently reading Herb Sutter's Exceptional C++ and More Exceptional C++. Lately I am not really working on a lot of C++ projects (only maintaining some old libraries from time to time), I mostly code in C# those days. But reading Exceptional C++ keeps my C++ knowledge up to date, plus trains switching my synapses. Some chapters are real puzzles. And I thought I knew about templates.
Other C++ books that I can highly recommend:
More on my Amazon C++ Listmania List.
Other C++ books that I can highly recommend:
- C++ Primer by Stanley B. Lippman, Josée Lajoie
- The C++ Programming Language by Bjarne Stroustrup
- Effective C++: 50 Specific Ways to Improve Your Programs and Design by Scott Meyers
- More Effective C++: 35 New Ways to Improve Your Programs and Designs by Scott Meyers
- Thinking in C++: Introduction to Standard C++ by Bruce Eckel
More on my Amazon C++ Listmania List.
Saturday, October 16, 2004
The Ultimate Geek Test
Eric Sink has assembled the ultimate geek test. It goes like this:
- In vi, which key moves the cursor one character to the right?
- What is the last name of the person who created Java?
- True or false: In the original episode IV, Greedo shot first.
Threadsafe GUI Programming
When I was working on Visual Chat back in 1998, I faced a severe performance problem when the chat client received data from the server, which caused some UI refreshing. Reason was that the TCP socket's receiving thread accessed Java AWT components directly, e.g. by setting a TextField's text, or by invoking Component.repaint().
I had not considered that while ordinary calls to Component.repaint() (within the main AWT event dispatch thread) are merged to one big paint effort once the thread runs idle, posting repaint events from another thread into the AWT event dispatch thread's (see below) queue causes constant repainting - a heavy performance issue. Once I figured out, it was easy to fix - I posted a custom event to the AWT thread's queue, which caused a call to Component.repaint() within the correct thread context, namely the AWT thread.
A connected issue is thread-safety. AWT Components or .NET Controls respectively their underlying native peers are not re-entrant, which makes it potentially dangerous to access them from any other thread than the one they were created on.
Once you think about it, it's quite obvious why thread-safety cannot be achieved like this: When one or more windows are being opened, the operating system associates them with the calling thread. Messages dedicated to the window will be posted to the thread's message queue. The thread then usually enters a message loop, where it receives user input, repainting and other messages dedicated to its windows. The message loop usually runs until the main window closes (signaled by the arrival of a WM_CLOSE message in case of Microsoft Windows).
The message loop implementation dispatches the messages to so called window functions, specific to each window class. A typical message loop implementation looks like this under Microsoft Windows:
Modal dialogs are based on "inner" message loops that lie on the current call stack, and exit once the modal window closes.
Java AWT hides this mechanism from the programmer. As soon as a Java window is being opened, the framework creates the AWT event dispatch thread, which gets associated with the window by the underlying operating system, and runs the message loop for this and all other Java windows. The main thread then blocks until the AWT event dispatch thread exits. The AWT event dispatch thread is also reponsible for repainting. It collects all GUI refresh events, checks which regions have been invalidated, and triggers painting them.
Under .NET WinForms, Application.Run() starts the message loop on the current thread.
So when someone calls any AWT-Component-method (or MFC-method resp. WinForms-method, if you prefer) from another thread, this bypasses the thread that actually runs the message loop. Most of those methods are supposed to be called within the thread that holds the message loop, e.g. because member variables are not protected by synchronization from concurrent access. So you actually run the risk of destroying your Component's data.
How can we spawn a worker thread then, which runs in parallel, hence keeps the GUI responsive, but can display some visual feedback, e.g. a dialog containing a progressbar and a cancel button? Yes we may always give Application.DoEvents() a try, but we might also want to invoke a Stored Procedure or a Webservice, which blocks program flow for several seconds. Then we need some kind of inter-thread communication, posting events to the message loop for example. The registered Window Function/EventHandler can then update the progressbar state or react on a button click. Its code will run inside the expected thread context.
Some years later I had to maintain somebody's old Java code, which just happened to behave in the same flawed way as described above. In the meantime, Swing offered some convenience methods for invoking funtionality inside the AWT event dispatch thread which I was happy to apply, namely SwingUtilities.invokeLater() and SwingUtilities.invokeAndWait(). The .NET WinForms API provides Control.Invoke() and Control.BeginInvoke(). The .NET WinForms library will actually throw an exception if any Control members are being accessed from another thread than the one that created it, hence runs the message loop.
I had not considered that while ordinary calls to Component.repaint() (within the main AWT event dispatch thread) are merged to one big paint effort once the thread runs idle, posting repaint events from another thread into the AWT event dispatch thread's (see below) queue causes constant repainting - a heavy performance issue. Once I figured out, it was easy to fix - I posted a custom event to the AWT thread's queue, which caused a call to Component.repaint() within the correct thread context, namely the AWT thread.
A connected issue is thread-safety. AWT Components or .NET Controls respectively their underlying native peers are not re-entrant, which makes it potentially dangerous to access them from any other thread than the one they were created on.
Once you think about it, it's quite obvious why thread-safety cannot be achieved like this: When one or more windows are being opened, the operating system associates them with the calling thread. Messages dedicated to the window will be posted to the thread's message queue. The thread then usually enters a message loop, where it receives user input, repainting and other messages dedicated to its windows. The message loop usually runs until the main window closes (signaled by the arrival of a WM_CLOSE message in case of Microsoft Windows).
The message loop implementation dispatches the messages to so called window functions, specific to each window class. A typical message loop implementation looks like this under Microsoft Windows:
MSG msg;
while (GetMessage(&msg, NULL, 0, 0)) {
TranslateMessage(&msg);
DispatchMessage(&msg);
}
Modal dialogs are based on "inner" message loops that lie on the current call stack, and exit once the modal window closes.
Java AWT hides this mechanism from the programmer. As soon as a Java window is being opened, the framework creates the AWT event dispatch thread, which gets associated with the window by the underlying operating system, and runs the message loop for this and all other Java windows. The main thread then blocks until the AWT event dispatch thread exits. The AWT event dispatch thread is also reponsible for repainting. It collects all GUI refresh events, checks which regions have been invalidated, and triggers painting them.
Under .NET WinForms, Application.Run() starts the message loop on the current thread.
So when someone calls any AWT-Component-method (or MFC-method resp. WinForms-method, if you prefer) from another thread, this bypasses the thread that actually runs the message loop. Most of those methods are supposed to be called within the thread that holds the message loop, e.g. because member variables are not protected by synchronization from concurrent access. So you actually run the risk of destroying your Component's data.
How can we spawn a worker thread then, which runs in parallel, hence keeps the GUI responsive, but can display some visual feedback, e.g. a dialog containing a progressbar and a cancel button? Yes we may always give Application.DoEvents() a try, but we might also want to invoke a Stored Procedure or a Webservice, which blocks program flow for several seconds. Then we need some kind of inter-thread communication, posting events to the message loop for example. The registered Window Function/EventHandler can then update the progressbar state or react on a button click. Its code will run inside the expected thread context.
Some years later I had to maintain somebody's old Java code, which just happened to behave in the same flawed way as described above. In the meantime, Swing offered some convenience methods for invoking funtionality inside the AWT event dispatch thread which I was happy to apply, namely SwingUtilities.invokeLater() and SwingUtilities.invokeAndWait(). The .NET WinForms API provides Control.Invoke() and Control.BeginInvoke(). The .NET WinForms library will actually throw an exception if any Control members are being accessed from another thread than the one that created it, hence runs the message loop.
Ten Years Of Netscape
Netscape is celebrating the 10th anniversary of its first browser release those days. On October 13th, 1994 Netscape Navigator, available for Microsoft Windows, Apple Macintosh, and X Window System environments, could be obtained via anonymous FTP from ftp.netscape.com.
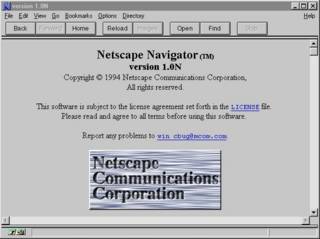
I remember the summer of 1994 was the first time I actually used Mosaic on an Apple Macintosh. I think it was not until early 1995 that I switched over to Netscape Navigator.
Its funny to note that Jim Clark and Marc Andreessen originally named their new company "Mosaic", but dropped that name after a dispute with the National Center for Supercomputing Applications, University of Illinios (NCSA), home of the original Mosaic browser, which had been developed under the lead of Marc Andreessen in 1993. Later on, some people seriously dared to doubt Andreessen's contributions to the Netscape browser development.
Jamie Zawinski, one of Netscape's original developers, still got his online diary running, recapitulating how working life looked like at Netscape in summer 1994. Later on, in 1998, a PBS documentation named "Code Rush" showed Netscape's struggle for keeping its browser market share.
I remember the summer of 1994 was the first time I actually used Mosaic on an Apple Macintosh. I think it was not until early 1995 that I switched over to Netscape Navigator.
Its funny to note that Jim Clark and Marc Andreessen originally named their new company "Mosaic", but dropped that name after a dispute with the National Center for Supercomputing Applications, University of Illinios (NCSA), home of the original Mosaic browser, which had been developed under the lead of Marc Andreessen in 1993. Later on, some people seriously dared to doubt Andreessen's contributions to the Netscape browser development.
Jamie Zawinski, one of Netscape's original developers, still got his online diary running, recapitulating how working life looked like at Netscape in summer 1994. Later on, in 1998, a PBS documentation named "Code Rush" showed Netscape's struggle for keeping its browser market share.
Thursday, October 14, 2004
Avoid Duplicate ADO.NET DataTable Events
Using ADO.NET DataSets, it's quite common to have some code like this:
When your DataTable has some EventHandlers attached, e.g. due to DataBinding, those EventHandlers will be notified several times about value changes. Also, indices will be rebuild more than once and the like. This might result in a whole cascade of additional calls and lead to slow runtime performance.
This drawback can be avoided by batching two or more data manipulations using DataTable.BeginLoadData() / DataTable.EndLoadData():
Another performance gain can be achieved by setting DataSet.EnforceConstraints to false (when not needed). This avoids constraint checks. In most of my .NET projects so far, it turned out to be better to let the database take care of constraint violations. Setting EnforceConstraints inside Visual Studio's XSD-Designer can be tricky. I didn't find the according property on the DataSet's property grid. But EnforceConstraints can be set manually within the XSD-file itself:
By the way, user interface controls bound to DataSets / DataTables resp. to IListSource-implementations are being repainted asynchronously on value changes in the underlying model. So luckily, several consecutive value changes lead to one repaint event only.
dataset.datatable.Clear();
dataset.Merge(anotherDataset.datatable);When your DataTable has some EventHandlers attached, e.g. due to DataBinding, those EventHandlers will be notified several times about value changes. Also, indices will be rebuild more than once and the like. This might result in a whole cascade of additional calls and lead to slow runtime performance.
This drawback can be avoided by batching two or more data manipulations using DataTable.BeginLoadData() / DataTable.EndLoadData():
try {
dataset.datatable.BeginLoadData();
dataset.datatable.Clear();
dataset.Merge(anotherDataset.datatable);
}
finally {
dataset.datatable.EndLoadData();
}Another performance gain can be achieved by setting DataSet.EnforceConstraints to false (when not needed). This avoids constraint checks. In most of my .NET projects so far, it turned out to be better to let the database take care of constraint violations. Setting EnforceConstraints inside Visual Studio's XSD-Designer can be tricky. I didn't find the according property on the DataSet's property grid. But EnforceConstraints can be set manually within the XSD-file itself:
<xs:element name="MyDataSet" msdata:IsDataSet="true"
msdata:EnforceConstraints="False">By the way, user interface controls bound to DataSets / DataTables resp. to IListSource-implementations are being repainted asynchronously on value changes in the underlying model. So luckily, several consecutive value changes lead to one repaint event only.
Wednesday, October 13, 2004
Bad Boy Ballmer
I just finished reading "Bad Boy Ballmer" by Frederic Alan Maxwell. The book was partly entertaining on one hand, on the other hand it didn't provide too much of new information to the well-informed reader. And: the usual Microsoft-bashing, dispensable to say the least. I wonder when unreflected Microsoft-bashing will finally go out of fashion.
Steve Ballmer protects his private life more than Bill Gates (Gates was and still is successfully promoted as the company's harmless chief nerd to the broader public by Microsoft's PR, while within the industry his business tactics are known to be merciless).
"Bad Boy Ballmer" also contains several hilarious bloopers on technology terms, I will just mention two of them:
Quote:
"By 2002 one could buy a Dell computer with 20 gigabytes - 20 billion bytes - of memory for less than eight hundred dollars. Given that IBM's 1981 Personal Computer had between zero and fortyeight thousand bytes of memory, a single, low-end 2002 Dell computer contains more than the memory of all the two hundred thousand IBM PCs sold in their first year combined."
Huh? The author seems to be confusing memory on a IBM PC as of 1981 with hard disk space on a Dell 2002 PC here. The first IBM PCs came with 16kB or 64kB, expandable to 256kB. 4GB is the current addressing limit on Win32 flat memory (although it can be extended up to 64GB using technologies like Physical Address Extension (PAE) on high-end Windows server versions). Dell's standard PCs of 2002 typically were equipped with 256MB or 512MB of memory.
Quote:
"Andreesen and Clark jointly established Netscape, its powerful search engine an outgrowth of Mosaic to the point that the University of Illinois threatened to sue."
Mosaic, Netscape a search engine? You can't be serious.
Did no one tech-savvy proof-read this? Hmmm... the book WAS ENTERTAINING after all. ;-)
Steve Ballmer protects his private life more than Bill Gates (Gates was and still is successfully promoted as the company's harmless chief nerd to the broader public by Microsoft's PR, while within the industry his business tactics are known to be merciless).
"Bad Boy Ballmer" also contains several hilarious bloopers on technology terms, I will just mention two of them:
Quote:
"By 2002 one could buy a Dell computer with 20 gigabytes - 20 billion bytes - of memory for less than eight hundred dollars. Given that IBM's 1981 Personal Computer had between zero and fortyeight thousand bytes of memory, a single, low-end 2002 Dell computer contains more than the memory of all the two hundred thousand IBM PCs sold in their first year combined."
Huh? The author seems to be confusing memory on a IBM PC as of 1981 with hard disk space on a Dell 2002 PC here. The first IBM PCs came with 16kB or 64kB, expandable to 256kB. 4GB is the current addressing limit on Win32 flat memory (although it can be extended up to 64GB using technologies like Physical Address Extension (PAE) on high-end Windows server versions). Dell's standard PCs of 2002 typically were equipped with 256MB or 512MB of memory.
Quote:
"Andreesen and Clark jointly established Netscape, its powerful search engine an outgrowth of Mosaic to the point that the University of Illinois threatened to sue."
Mosaic, Netscape a search engine? You can't be serious.
Did no one tech-savvy proof-read this? Hmmm... the book WAS ENTERTAINING after all. ;-)
Monday, October 11, 2004
AllowSetForegroundWindow
Starting with Windows ME/2000, applications not running in the foreground can not bring their windows to the front. You usually see their taskbar button blink when they are trying to do so, e.g. by invoking SetForegroundWindow().
Unfortunately one of our older applications was actually split in two processes, which communicate to each other using TCP sockets. Both applications have graphical user interface. As customers (who never really saw two applications but just one GUI) started to switch from Windows NT to 2000/XP, they noticed that newly created windows were overlapped or completely hidden by others. As a temporary workaround (which was only available under XP) they started the application in NT compatibility mode.
The remedy came with a new API-function, AllowSetForegroundWindow(). The foreground process can allow any other process to bring windows to the front. All it needs to know is the target process's id. And of course timing is crucial, once the invoking process is not the foreground process any more, it cannot allow other process to open foreground windows either. Clearly one has to check the proper windows version before invoking AllowSetForegroundWindow(). This can be done using GetVersion().
Unfortunately one of our older applications was actually split in two processes, which communicate to each other using TCP sockets. Both applications have graphical user interface. As customers (who never really saw two applications but just one GUI) started to switch from Windows NT to 2000/XP, they noticed that newly created windows were overlapped or completely hidden by others. As a temporary workaround (which was only available under XP) they started the application in NT compatibility mode.
The remedy came with a new API-function, AllowSetForegroundWindow(). The foreground process can allow any other process to bring windows to the front. All it needs to know is the target process's id. And of course timing is crucial, once the invoking process is not the foreground process any more, it cannot allow other process to open foreground windows either. Clearly one has to check the proper windows version before invoking AllowSetForegroundWindow(). This can be done using GetVersion().
Sunday, October 10, 2004
WinForms UserControl DataBinding
Last week I worked on a UserControl which provided a bindable property. Our GUI developer bound it to a DataTable's column, but what happened at runtime was that while binding the property worked just fine, the bound DataRow's RowState was set to "Modified" each time, even when no user input had occurred on the control. In this case the RowState was expected to stay as "Unchanged".
I spent hours on searching the internet, until I finally found the reason why: There seems to be an undocumented naming convention inside .NET DataBinding: One must provide a public event of the following kind...
... and fire the event when the bound property is set:
Hello, can someone there at MSDN please update the DataBinding documentation? Or did I miss something?
I spent hours on searching the internet, until I finally found the reason why: There seems to be an undocumented naming convention inside .NET DataBinding: One must provide a public event of the following kind...
public event EventHandler PropertynameChanged;
... and fire the event when the bound property is set:
public object Propertyname {
get {
// return the property value
}
set {
// set the property value,
// then fire the event (in case the value changed)
if (PropertynameChanged != null) {
PropertynameChanged(this, EventArgs.Empty);
}
}
}
Hello, can someone there at MSDN please update the DataBinding documentation? Or did I miss something?
Saturday, October 09, 2004
Suffering From The Not-Invented-Here Syndrome
Amazingly (and I have been watching this for years), there are still organizations out there that try to re-invent the wheel as often as they can. I am talking about people that happily keep on building their own project-specific windowing toolkit, standard gui controls, collection implementations, XML-parsers, HTTP-protocols, object-relational-mapping layers, report engines, content management systems, workflow systems, you name it.
Typically those organizations are either departments within larger corporations, who in some way or another gained a jester's license, while the corporation swallows the costs of their doomed endeavours, or small startup vendors that managed to convince a clueless customer about the absolute necessity for their futile product. Customers that just don't know they could get a better product for a fraction amount or even for free from somewhere else, without the pain of being the vendor's guinea pig for an unproven technology, that no one else uses.
Sometimes it's cool to be an early adopter. But then let me be an early adopter of something innovative that really fits my needs, and not the 47th clone of another "have-been-there-before"-product from the little ISV next door.
Please, stop this insanity. Let's do what we were supposed to do: Develop Applications. Leave the other stuff to the experts...
Typically those organizations are either departments within larger corporations, who in some way or another gained a jester's license, while the corporation swallows the costs of their doomed endeavours, or small startup vendors that managed to convince a clueless customer about the absolute necessity for their futile product. Customers that just don't know they could get a better product for a fraction amount or even for free from somewhere else, without the pain of being the vendor's guinea pig for an unproven technology, that no one else uses.
Sometimes it's cool to be an early adopter. But then let me be an early adopter of something innovative that really fits my needs, and not the 47th clone of another "have-been-there-before"-product from the little ISV next door.
Please, stop this insanity. Let's do what we were supposed to do: Develop Applications. Leave the other stuff to the experts...
Thursday, October 07, 2004
The Fallacy Of Cheap Programmers
Robin Sharp writes about "The Fallacy Of Cheap Programmers":
A lot of research on programmer productivity shows that the best programmers are up to 20 times more productive than the worst programmers. If the income differential between the best and worst programmers is even 5 times, it means employers are getting incredible value for money hiring the best programmers.
Why then don't companies hire a few very good programmers and leave the rest flipping Big Macs? There is one very good reason: the psychology of managers. Managers simply can't believe that one programmer can be as productive as 3, let alone 5 or even 20 times. Managers believe that productivity is a management issue.
They believe that simply by re-organising their human resources it is they who can gain leaps in productivity, and reap the rewards. But the reality of management, as we all know, is that most projects are late and over budget.
I could not agree more, Robin.
A lot of research on programmer productivity shows that the best programmers are up to 20 times more productive than the worst programmers. If the income differential between the best and worst programmers is even 5 times, it means employers are getting incredible value for money hiring the best programmers.
Why then don't companies hire a few very good programmers and leave the rest flipping Big Macs? There is one very good reason: the psychology of managers. Managers simply can't believe that one programmer can be as productive as 3, let alone 5 or even 20 times. Managers believe that productivity is a management issue.
They believe that simply by re-organising their human resources it is they who can gain leaps in productivity, and reap the rewards. But the reality of management, as we all know, is that most projects are late and over budget.
I could not agree more, Robin.
Tuesday, October 05, 2004
Pat Helland Sings "Bye Bye Mr. CIO Guy"
Pat Helland (Microsoft Architect) sings "Bye Bye Mr. CIO Guy" on Channel9. Guess who plays the Guitar: Mr. COM / Mr. Indigo himself, Don Box.
Object-Relational Technologies = Vietnam?
Ted Neward posted a critical article regarding O/R Mapping Tools. He states: "Object-relational technologies are the Vietnam of the Computer Science industry."
Is this why Microsoft slipped ObjectSpaces from Whidbey to WinFS? If not even Microsoft can get it right, do you seriously think the little ISV next door can? On the other side, Hibernate seems to do a good job on that (although I have not tried it in detail yet), and I have also applied Container-Managed Entity EJBs under certain scenarios in some J2EE projects, which just worked fine.
Still it seems that projects using O/R often harvest far more problems than benefits. Especially those that follow an undifferentiated 100% O/R approach. Might it be that people listen too much to pied piper consultants? Or even worse, some think they must implement their own O/R Mapping Layer. Don't burn your fingers, this is by no means at all a trivial task.
The following quote from Ted's article sounds like the accurate summary of a real project I know of (luckily, I have only been watching it from the outside):
Both major software vendors and project teams (building their own O-R layer) fall into the same trap. With object-relational technologies, products begin by flirting with simple mappings: single class to single table, building simple Proxies that do some Lazy Loading, and so on. "Advisers" are sent in to the various project teams that use the initial O-R layer, but before long, those "advisers" are engaging in front-line coding, wrestling with ways to bring object inheritance to the relational database.
By the time of the big demo, despite there being numerous hints that people within the project team are concerned, project management openly welcomes the technology, praising productivity gains and citing all sorts of statistics about how wonderful things are going, including "lines of code" saved, how we were writing far more useful code than bugs. Behind the scenes, however, project management is furious at the problems and workarounds that have arisen, and frantically try every avenue they can find to find a way out: consultants, more developers, massive code reviews, propping up the existing infrastructure by throwing more resources at it, even supporting then toppling different vendors' products as a means of solving the problem.
Nothing offers the solution the team needs, though: success, a future migration path, or at the very least, a way out preserving the existing investment. Numerous "surprises" (such as the N+1 query problem thanks to lazy-loading proxies or massive bandwidth consumption thanks to eager-loading policies) make the situation more critical.
Finally, under new management (who promise to fix the situation and then begin by immediately looking to use the technology in other projects), the team seizes on a pretext, ship the code and hand it off to system administrators to deploy, and bring the developers home to a different project. Not a year later, the project is cancelled and pulled from the servers, the project's defeat complete in all but name.
Is this why Microsoft slipped ObjectSpaces from Whidbey to WinFS? If not even Microsoft can get it right, do you seriously think the little ISV next door can? On the other side, Hibernate seems to do a good job on that (although I have not tried it in detail yet), and I have also applied Container-Managed Entity EJBs under certain scenarios in some J2EE projects, which just worked fine.
Still it seems that projects using O/R often harvest far more problems than benefits. Especially those that follow an undifferentiated 100% O/R approach. Might it be that people listen too much to pied piper consultants? Or even worse, some think they must implement their own O/R Mapping Layer. Don't burn your fingers, this is by no means at all a trivial task.
The following quote from Ted's article sounds like the accurate summary of a real project I know of (luckily, I have only been watching it from the outside):
Both major software vendors and project teams (building their own O-R layer) fall into the same trap. With object-relational technologies, products begin by flirting with simple mappings: single class to single table, building simple Proxies that do some Lazy Loading, and so on. "Advisers" are sent in to the various project teams that use the initial O-R layer, but before long, those "advisers" are engaging in front-line coding, wrestling with ways to bring object inheritance to the relational database.
By the time of the big demo, despite there being numerous hints that people within the project team are concerned, project management openly welcomes the technology, praising productivity gains and citing all sorts of statistics about how wonderful things are going, including "lines of code" saved, how we were writing far more useful code than bugs. Behind the scenes, however, project management is furious at the problems and workarounds that have arisen, and frantically try every avenue they can find to find a way out: consultants, more developers, massive code reviews, propping up the existing infrastructure by throwing more resources at it, even supporting then toppling different vendors' products as a means of solving the problem.
Nothing offers the solution the team needs, though: success, a future migration path, or at the very least, a way out preserving the existing investment. Numerous "surprises" (such as the N+1 query problem thanks to lazy-loading proxies or massive bandwidth consumption thanks to eager-loading policies) make the situation more critical.
Finally, under new management (who promise to fix the situation and then begin by immediately looking to use the technology in other projects), the team seizes on a pretext, ship the code and hand it off to system administrators to deploy, and bring the developers home to a different project. Not a year later, the project is cancelled and pulled from the servers, the project's defeat complete in all but name.
Monday, October 04, 2004
Knowing Java But Not Having A Clue?
Some years ago, I had the pleasure to program some archaic embedded systems, namely mobile phones, based on a 16bit CPU with a segmented memory model (comparable to the old 8086 memory model). We wrote an application framework (windowing system, scheduler, network stack API and the like) applying a C++ compiler/linker (which had just introduced some brand-new C++ features like templates in its latest version ;-) ). This framework represented the technological base for several customer projects.
Our department was growing, so we employed some recent university graduates. The course curriculum here in Austria allows you to walk through a computer science degree without writing a single line of C or C++ (not to mention assembler).
We didn't really let them touch any core stuff, but still: The new hires started coding as they used to code in their assignment classes under Java: highly inefficient, producing one memory leak after the other, not knowing about the consequences of their code - especially on a system with very limited resources.
Some of them didn't know the implications of a copy constructor invocation (heck, they didn't even know they would invoke a copy constructor on a value assignment - they simply thought they would be working on references as they used to). One time a new hire allocated and free'd memory at such a high rate that we faced serious performance and memory fragmentation problems just because of scrolling through some listbox items (several hundred malloc's and free's during a single keypress).
And just recently I spent half an hour or so explaining our current summer intern the difference between stack and heap. In his Java times at university he never had to worry about that...
For someone who as been programming C++ for several years, it is not too hard to switch to a managed environment that provides garbage collection and the like, as Java or .NET do. OK, some new concepts, but it's a lot of convenience.
What computer science professors tend to forget is that the opposite course is likely to happen as well to those graduates once they enter working life (those who have only applied Java or C#). There is more than Java and C# out there. And this "backward" paradigm shift is a much more difficult one. Appointing inexperienced Java programmers to a C++ or C project is a severe project risk.
Our department was growing, so we employed some recent university graduates. The course curriculum here in Austria allows you to walk through a computer science degree without writing a single line of C or C++ (not to mention assembler).
We didn't really let them touch any core stuff, but still: The new hires started coding as they used to code in their assignment classes under Java: highly inefficient, producing one memory leak after the other, not knowing about the consequences of their code - especially on a system with very limited resources.
Some of them didn't know the implications of a copy constructor invocation (heck, they didn't even know they would invoke a copy constructor on a value assignment - they simply thought they would be working on references as they used to). One time a new hire allocated and free'd memory at such a high rate that we faced serious performance and memory fragmentation problems just because of scrolling through some listbox items (several hundred malloc's and free's during a single keypress).
And just recently I spent half an hour or so explaining our current summer intern the difference between stack and heap. In his Java times at university he never had to worry about that...
For someone who as been programming C++ for several years, it is not too hard to switch to a managed environment that provides garbage collection and the like, as Java or .NET do. OK, some new concepts, but it's a lot of convenience.
What computer science professors tend to forget is that the opposite course is likely to happen as well to those graduates once they enter working life (those who have only applied Java or C#). There is more than Java and C# out there. And this "backward" paradigm shift is a much more difficult one. Appointing inexperienced Java programmers to a C++ or C project is a severe project risk.
Sunday, October 03, 2004
The J2EE Tutorial, Second Edition
I don't receive any commission on that, but "The J2EE Tutorial, Second Edition" (Addison Wesley) is an excellent book which provides a good overview over all technologies that lie under the hood of J2EE 1.4.


Subscribe to:
Comments (Atom)