- Joel On Software (December 29th, 2005): The Perils Of JavaSchools
- Arno's Software Development Weblog (October 4th, 2004): Knowing Java But Not Having A Clue?

Saturday, December 31, 2005
A Luminary Is On My Side (II)
A luminary is on my side (hey, not for the first time):
Friday, December 30, 2005
As A Software Developer, You Don't Live On An Island (Part II)
Yesterday I talked about the fact that as software developers, we should be prepared for change.
But of course, there is the other extreme as well. Self-taught semi-professionals missing real project experience as well as the feedback of more adept peers. Those who jump on the bandwagon of every hype, but do so in a fundamentally flawed way.
Like the guys who took the "a real man writes his own web framework"-joke for serious, and invested several man-years in a doomed attempt to create a chimera that combined web user interface components and object-relational mapping (and by "combine" I mean tight coupling, you bet) - just because they didn't like Struts or Hibernate, and quote: "Java Server Faces are still in Beta". They also didn't like the Java Collections API, so they wrote their own (interface-compatible) implementation.
Another developer was so convinced of webservices and any other technology that he could possibly apply that he suggested to compile report layouts into .NET assemblies, store those assemblies in database BLOBS and download them to the intranet(!) client using webservices (byte-arrays serialized over XML). Need to say more?
But of course, there is the other extreme as well. Self-taught semi-professionals missing real project experience as well as the feedback of more adept peers. Those who jump on the bandwagon of every hype, but do so in a fundamentally flawed way.
Like the guys who took the "a real man writes his own web framework"-joke for serious, and invested several man-years in a doomed attempt to create a chimera that combined web user interface components and object-relational mapping (and by "combine" I mean tight coupling, you bet) - just because they didn't like Struts or Hibernate, and quote: "Java Server Faces are still in Beta". They also didn't like the Java Collections API, so they wrote their own (interface-compatible) implementation.
Another developer was so convinced of webservices and any other technology that he could possibly apply that he suggested to compile report layouts into .NET assemblies, store those assemblies in database BLOBS and download them to the intranet(!) client using webservices (byte-arrays serialized over XML). Need to say more?
Thursday, December 29, 2005
As A Software Developer, You Don't Live On An Island (Part I)
Maybe my expectations are too high, but how come that so many software developers suffer from the ostrich syndrome? They have been doing their RPG or Visual Basic or SQLWindows or <place_your_favorite_outdated_technology_here> programming for ten years or longer, but during all that time they never managed to look beyond their own nose. Now they suddenly face a migration to Java or VB.NET, or they must provide a webservice interface or the like. OOP, what's that? Unicode, what's that? XML, that looks easy, let's just do some printf()s (or whatever the RPG counterpart to printf() is ;-) ) with all these funny brackets. Oh, and when there is something new to learn, those folks of course expect their employer to send them on training for months.
I always thought this profession would mainly attract people who embrace change. Seems I was wrong.
Besides everyday project business, I try to stay in touch with the latest in technology. Readings books, magazines and weblogs, listening to podcasts, talking with colleagues who are into some new stuff, and the like.
Reading one book a month about something you haven't dealt yet (may it be a C# primer or a Linux admin tutorial or whatever) - that's the minimum I recommend to every software developer with some sense of personal responsibility.
I always thought this profession would mainly attract people who embrace change. Seems I was wrong.
Besides everyday project business, I try to stay in touch with the latest in technology. Readings books, magazines and weblogs, listening to podcasts, talking with colleagues who are into some new stuff, and the like.
Reading one book a month about something you haven't dealt yet (may it be a C# primer or a Linux admin tutorial or whatever) - that's the minimum I recommend to every software developer with some sense of personal responsibility.
Wednesday, December 28, 2005
Seven Habits Of Highly Effective Programmers
"Seven Habits of Highly Effective Programmers" is one of several excellent articles on technicat.com.
Wednesday, December 21, 2005
LINQ
LINQ or "Language Integrated Query" will be part of .NET 3.0 - absolutely amazing stuff. I have to admit I am still rubbing my eyes - did Anders Hejlsberg just solve the object/relational mismatch as well as making painful XML programming models like DOM or XPath obsolete? Let's wait and see...
Now I have not really been too fond of one or two C# language constructs (don't get me wrong, the features themselves are great, it's just their syntax flavor - e.g. the way the notion of delegates and events looks like), but I have always admired Hejlsberg (of Turbo Pascal, Delphi and C# fame, for those who don't know) and his achievements for our industry. And LINQ really seems to be the icing on the cake.
Now I have not really been too fond of one or two C# language constructs (don't get me wrong, the features themselves are great, it's just their syntax flavor - e.g. the way the notion of delegates and events looks like), but I have always admired Hejlsberg (of Turbo Pascal, Delphi and C# fame, for those who don't know) and his achievements for our industry. And LINQ really seems to be the icing on the cake.
Thursday, December 15, 2005
30 Years Of Personal Computer
Nice article about 30 Years Of Personal Computer, just one doubt: Did the Tandy-Radio Shack 80 really outsell the Apple II in the late 70s? I always assumed Apple was market leader until the introduction of the IBM PC.

By the way, we both had a TRS-80 and some Commodore CBMs side by side at school but we only used the Commodore, because to us it somehow seemed cooler.

By the way, we both had a TRS-80 and some Commodore CBMs side by side at school but we only used the Commodore, because to us it somehow seemed cooler.
Saturday, December 10, 2005
Object Oriented Crimes
80% of software development is maintenance work. That's reality, and I don't complain about that. I also don't complain about having to dig through other people's code that is sometimes hard to understand. It's just the same as when looking at some of my own old work - the design mistakes of the past are pretty obvious today. Maybe it was just that you had to find a pragmatic solution under project schedule pressure back then - it might not be beautiful, but it worked.
But then there are also programming perversions that are simply beyond good and evil (similar to the ones posted on The Daily WTF). Let me give you two examples - coincidentally each of those came from German vendors...
Case #1:
Java AWT UI (yes, the old days...), card layout, so there is one form visible at a time and the other forms are sent to the back. Now those UI classes need to exchange data, and this was achieved by putting all data into protected static variables in the base class, so that all derived classes could access it. Beautiful, isn't it? But that's not the whole story. Those static variables weren't business objects in the common sense - they were plain stupid string arrays. One array for each business object attribute (and of course, each datatype was represented by a string), and the actual "object" was identified by the array index. You know, something like this:
The memory alone still makes me shudder today...
Case #2:
Years later, this time we talk about a .NET WinForms application. Somehow the development lead had heard that it's a good idea to separate visualization from business model, so he invented two kinds of classes: UI classes and business object classes. Doesn't sound too bad? Well, first of all he kind of forgot about the third layer (data access, that's it!), and spilled his SQL statements all over his business objects. And by that I don't mean that you could read your SQL statement in clear text. No, they were created by a bizarre concatenated mechanism, which included the concept of putting some parts of the SQL code in base classes (re-use, you know), and distribute the rest over property getters within the derived classes. And this SQL code did not only cover business-relevant logic, it was also responsible for populating completely unrelated UI controls. The so called "business object" also contained information about which grid row or which tab page had been selected by the user - yeah, talking about interpretating another OO concept completely wrong. The Model-View-Controller design pattern is all about loose coupling, so that models can be applied with different views.
Uuuh, I try to repress the thought about it, but it keeps coming back...
For a developer, being able to start a project without this kind of legacy burden is a blessing. I appreciate it each time management decides to trust its own people to build up something from scratch, instead of buying in third party garbage like that.
But then there are also programming perversions that are simply beyond good and evil (similar to the ones posted on The Daily WTF). Let me give you two examples - coincidentally each of those came from German vendors...
Case #1:
Java AWT UI (yes, the old days...), card layout, so there is one form visible at a time and the other forms are sent to the back. Now those UI classes need to exchange data, and this was achieved by putting all data into protected static variables in the base class, so that all derived classes could access it. Beautiful, isn't it? But that's not the whole story. Those static variables weren't business objects in the common sense - they were plain stupid string arrays. One array for each business object attribute (and of course, each datatype was represented by a string), and the actual "object" was identified by the array index. You know, something like this:
protected static String[] employeeFirstName;
protected static String[] employeeLastName;
protected static String[] employeeIncome;
protected static int currentEmployee;The memory alone still makes me shudder today...
Case #2:
Years later, this time we talk about a .NET WinForms application. Somehow the development lead had heard that it's a good idea to separate visualization from business model, so he invented two kinds of classes: UI classes and business object classes. Doesn't sound too bad? Well, first of all he kind of forgot about the third layer (data access, that's it!), and spilled his SQL statements all over his business objects. And by that I don't mean that you could read your SQL statement in clear text. No, they were created by a bizarre concatenated mechanism, which included the concept of putting some parts of the SQL code in base classes (re-use, you know), and distribute the rest over property getters within the derived classes. And this SQL code did not only cover business-relevant logic, it was also responsible for populating completely unrelated UI controls. The so called "business object" also contained information about which grid row or which tab page had been selected by the user - yeah, talking about interpretating another OO concept completely wrong. The Model-View-Controller design pattern is all about loose coupling, so that models can be applied with different views.
Uuuh, I try to repress the thought about it, but it keeps coming back...
For a developer, being able to start a project without this kind of legacy burden is a blessing. I appreciate it each time management decides to trust its own people to build up something from scratch, instead of buying in third party garbage like that.
Sunday, November 27, 2005
My Favorite Software Technology Webcasts / Podcasts
Sorry, no longish postings those days, as I am in release crunch mode right now. In the meantime, you might want to check out what I consider some of the most interesting software technology webcats / podcasts out there:
I listen to them on a daily basis using an iPOD shuffle during my way from / to work.
I listen to them on a daily basis using an iPOD shuffle during my way from / to work.
Saturday, November 19, 2005
ADO.NET Transactions, DataAdapter.Update() And DataRow.RowState
I guess that almost every ADO.NET developer stumbles upon this sooner or later... as we all know, DataAdapter.Update() invokes DataRow.AcceptChanges() after a successful DB-update/-insert/-delete. But what if that whole operation happened within a transaction, and a rollback occurs later on during that process? Our DataRow's RowState has already changed from Modified/Added/Deleted to Unchanged (resp. Detached in case of a delete), our DataRowVersions are lost, hence our DataSet does not reflect the rollback that happened on the database.
What we are doing so far in our projects is to work on a copy of the original DataSet, so we can perform a "rollback" in memory as well. In detail, we merge back DataRow by DataRow, which allows us to keep not only its original RowState, but also different DataRowVersions (Original, Current, Proposed and the like). This is essential for subsequent updates to work properly.
But merging thousands of DataRows has a huge performance penalty (esp. if you got Guids as primary keys - this might be caused by a huge number of primary key comparisons, but I am not really sure about that), which sometimes forces us to disable that whole feature, and do a complete reload from the DB after an update instead (but then again, this will wipe pending updates which were rolled back).
So right now I am looking for a faster alternative. ADO.NET 2.0 provides a new DataAdapter property, namely DataAdapter.AcceptChangesDuringUpdate. This is exactly what we need, but we are still running under .NET 1.1.
Microsoft ADO.NET guru David Sceppa came up with another approach:
If you want to keep the DataAdapter from implicitly calling AcceptChanges after submitting the pending changes in a row, handle the DataAdapter's RowUpdated event and set RowUpdatedEventArgs to UpdateStatus.SkipCurrentRow.
That is actually what I will try to do next.
What we are doing so far in our projects is to work on a copy of the original DataSet, so we can perform a "rollback" in memory as well. In detail, we merge back DataRow by DataRow, which allows us to keep not only its original RowState, but also different DataRowVersions (Original, Current, Proposed and the like). This is essential for subsequent updates to work properly.
But merging thousands of DataRows has a huge performance penalty (esp. if you got Guids as primary keys - this might be caused by a huge number of primary key comparisons, but I am not really sure about that), which sometimes forces us to disable that whole feature, and do a complete reload from the DB after an update instead (but then again, this will wipe pending updates which were rolled back).
So right now I am looking for a faster alternative. ADO.NET 2.0 provides a new DataAdapter property, namely DataAdapter.AcceptChangesDuringUpdate. This is exactly what we need, but we are still running under .NET 1.1.
Microsoft ADO.NET guru David Sceppa came up with another approach:
If you want to keep the DataAdapter from implicitly calling AcceptChanges after submitting the pending changes in a row, handle the DataAdapter's RowUpdated event and set RowUpdatedEventArgs to UpdateStatus.SkipCurrentRow.
That is actually what I will try to do next.
Friday, November 18, 2005
Tuesday, November 15, 2005
Latest Purchase On Thinkgeek.Com
The "Binary Dad" t-shirt

In order to save on overseas shipping costs, we always pool our orders. Top item among my friends' orders this time was the "Schrödinger's Cat Is Dead" t-shirt.



In order to save on overseas shipping costs, we always pool our orders. Top item among my friends' orders this time was the "Schrödinger's Cat Is Dead" t-shirt.


Friday, November 11, 2005
Is MS Windows Ready For The Desktop?
No offense intended, I am myself a very Windows-centric developer, but "Is MS Windows Ready For The Desktop" is just too funny!
So now comes partitioning. Since I know from Linux that NTFS is a buggy file system (never got it to work smooth under Linux), I choose the more advanced FAT-fs, since there's no other option, this should be right for me. It's a disappointment I can't implement volume management tools like LVM or EVMS, or an initrd, but I decide to forget about this and go on, believing the Windows-team has made the right decision by not supporting this cumbersome features. So this means, I can forget about software-RAID and hard disk encryption supported by the kernel. But what about resizing partitions? Steve explains, this can be done in Windows. You go to your software-supplier, ask for the free Partition Magic 8.0, and after paying your €55 NVC, the Partition Magic CD can do a (tiny) part of the stuff EVMS can, like resizing.
So now comes partitioning. Since I know from Linux that NTFS is a buggy file system (never got it to work smooth under Linux), I choose the more advanced FAT-fs, since there's no other option, this should be right for me. It's a disappointment I can't implement volume management tools like LVM or EVMS, or an initrd, but I decide to forget about this and go on, believing the Windows-team has made the right decision by not supporting this cumbersome features. So this means, I can forget about software-RAID and hard disk encryption supported by the kernel. But what about resizing partitions? Steve explains, this can be done in Windows. You go to your software-supplier, ask for the free Partition Magic 8.0, and after paying your €55 NVC, the Partition Magic CD can do a (tiny) part of the stuff EVMS can, like resizing.
Wednesday, November 09, 2005
Lotus Notes
Let me talk about Lotus Notes today (the client only, as this is all I know about - and by the way, this is why the UI matters so much: users just don't care about fancy server stuff like sophisticated data replication, they care about their experience on the frontend side of things). I mean some people have learned to swallow the bitter pill, quietly launching their little KillNotes.exe in order to restart Notes after each crash without having to reboot the whole system. Others may curse on a daily basis (Survival of the Unfittest, Lotus Notes Sucks, "Software Tools of Dirt"-Page (in German), I hate Notes, Interface Hall of Shame or Notes Sucks come to mind). As for myself, I am just going to calmly describe how working with Lotus Notes looks like:
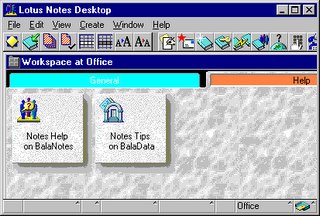
This screenshot shows a typical Lotus Notes 4.5 workplace as of 1996. Notes 5.0, which shipped in 1999, looks pretty much the same and is still widely used today.
As far as I have heard some things have been improved in Notes 6.5, while others haven't. But you know, large corporations sometimes skip one major release on their installation base, because of the effort involved in updating all the clients or because they couldn't migrate their applications built on top of it or whatever. This just proves that software tends to stay around longer than some vendors originally anticipated.
Jeff Atwood - as usual - sums things up pretty accurately:
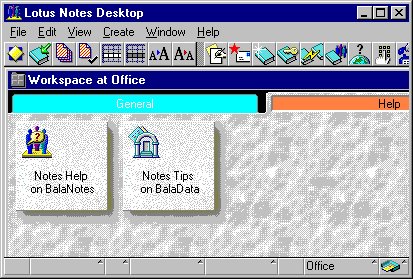
This screenshot shows a typical Lotus Notes 4.5 workplace as of 1996. Notes 5.0, which shipped in 1999, looks pretty much the same and is still widely used today.
- The Notes client crashes when doing a search, it crashes when inserting data from the clipboard, it crashes on all kinds of occasions, and the stuff you worked on is gone. No draft folder, nothing.
- After Notes crashes, there is no way to restart it, because some processes remain in a zombie-like state. Luckily there is KillNotes. It is even available from an IBM download site. Think about it, instead of fixing those crashes, or instead of avoiding zombie processes being left behind after crashing, they did the third-best thing: provide a tool to clean up those zombie-processes. Of course out of the 100 million Lotus Notes users worldwide, maybe 1% have ever heard of that tool at all.
- The UI is... special. The Look & Feel is incomparable to anything else you might know. Most famous: The "You have mail"-Messagebox - pops up, even when you are typing in another application. Makes you switch to your inbox, where you find - nothing. No new mail. UI controls that look and behave completely different than what the standards of the underlying operating system would suggest. Modeless dialogs for text formatting. Undo rarely ever works. Pasting some HTML or RichText data from the clipboard blocks the system for several seconds. There is no toolbar icon for refreshing the current list of documents (e.g. mail inbox) - refreshing happens when you click into a grey window area (you'd better know about it!). Forms do not provide comboboxes for listing values to choose from, only modal dialogs that open up and contain listboxes. Icons don't comply with the desktop's standard, e.g. the icon for clipboard pasting is a a pin, the icon for saving is a book. Grids are not interactive, e.g. no way to change column order, only rudimentary grid sorting. And so on and so on...
- When sent to the background, the client sometimes starts consuming CPU power (up to 90%) - slowing down the foreground application, doing I don't know what. As soon as you bring it to the front - back to 0%. Like a little child saying "It wasn't me". "Un-cooperative multitasking" at its best (I wonder what would have happened during the non-preemptive days of 16bit-Windows).
- Text search: Runs in the main UI thread, so it blocks the whole application until it's done - and this might take a looong time. I don't know for sure, but it's so slow I suspect it has no fulltext index, thus has to scan each and every document again and again. And if that's not the case, its index seek implementation must be bogus. Anyway, more often than not the search result is just plainly wrong - documents that clearly should appear simply don't show up. Searches are only possible for one criteria, not more than that.
- From time to time Notes causes flickering by senselessly repeated window repainting.
- There are those constant security messages popping up, that keep on asking whether to create a counter certificate or whatever in order to be able to access certain documents. I have a degree in computer science, but I find these messages completely incomprehensible. Go figure how much the average end-user will enjoy that.
- All those weaknesses are - per-definitionem - inherited by most Lotus Notes applications.
As far as I have heard some things have been improved in Notes 6.5, while others haven't. But you know, large corporations sometimes skip one major release on their installation base, because of the effort involved in updating all the clients or because they couldn't migrate their applications built on top of it or whatever. This just proves that software tends to stay around longer than some vendors originally anticipated.
Jeff Atwood - as usual - sums things up pretty accurately:
We've all had bad software experiences. However, at my last job, our corporate email client of choice was Lotus Notes. And until you've used Lotus Notes, you haven't truly experienced bad software. It is death by a thousand tiny annoyances - the digital equivalent of being kicked in the groin upon arrival at work every day.
Lotus Notes is a trainwreck of epic (enterprise?) proportions, but it's worth studying to learn what not to do when developing software.
Thank You McAfee
So second level support calls in: "Listen, one customer installed our application, but he keeps on insisting that the user interface is all empty". "Yeah right", you think, thanking god that you don't have to answer hotline calls.
A quick Google search brings up a well-known suspect: McAfee AntiVirus. According to this Microsoft knowledge base article, McAfee's buffer overflow protection feature can screw WinForms applications - and that's exactly what had happened at the customer's site. Luckily there is a patch available.
BTW, I stopped using McAfee privately when they changed their virus definition subscription model - I hate to pay for a program that literally expires after 12 months.
A quick Google search brings up a well-known suspect: McAfee AntiVirus. According to this Microsoft knowledge base article, McAfee's buffer overflow protection feature can screw WinForms applications - and that's exactly what had happened at the customer's site. Luckily there is a patch available.
BTW, I stopped using McAfee privately when they changed their virus definition subscription model - I hate to pay for a program that literally expires after 12 months.
Friday, November 04, 2005
First Impressions Of Visual Studio 2005 RTM
I installed Visual Studio 2005 RTM yesterday, and - as a first endurance test - tried to convert one of our larger Visual Studio 2003 projects to the new environment. The conversion finished successfully, but the compilation raised several errors:
After fixing those issues, our application could be built. But I faced runtime problems as well, e.g. a third party library (for XML encryption) which suddenly produced invalid hash results (sidenote: XML encryption is now supported by .NET 2.0 - my colleagues and me were joking that this might be just another case of DOS Ain't Done 'Til Lotus Won't Run).
Don't get me wrong, Visual Studio 2005 is a cool product with lots of long-awaited features. When starting a project from scratch, I would be tempted to jump board on 2005. But with .NET 1.1 legacy projects lying around, there is just no way we can migrate to 2005 yet.
By the way, wiping an old Visual Studio 2005 Beta or CTP version is a nightmare (you are expected to manually uninstall up to 23 components in the correct order)! Luckily Dan Fernandez helped out with the Pre-RTM Visual Studio 2005 Automatic Uninstall Tool.
- One self-assignment ("a = a") caused an error (this was not even a warning under .NET 1.1), I guess this can be toggled by lowering the compiler warning level. Anyway it is a good thing the compiler pointed that out, as the developer's intention clearly was to write "this.a = a". Luckily the assignment to "this.a" happened already in the base class as well.
- Typed Datasets generated by the IDE are not backward compatible, as the access modifiers for InitClass() have changed to "private". We had a subclass which tried to invoke base.InitClass(), hence broke the build.
- The new compiler spit out several naming collision errors, when equally named third party components were not access through their fully qualified names (although in the code context, due to the type they were assigned to, it was clear which type to use) The .NET 1.1 compiler used to have no problem with that.
- Visual Studio 2005 also crashed once during compilation. I had to compile one project individually in order to get ahead.
After fixing those issues, our application could be built. But I faced runtime problems as well, e.g. a third party library (for XML encryption) which suddenly produced invalid hash results (sidenote: XML encryption is now supported by .NET 2.0 - my colleagues and me were joking that this might be just another case of DOS Ain't Done 'Til Lotus Won't Run).
Don't get me wrong, Visual Studio 2005 is a cool product with lots of long-awaited features. When starting a project from scratch, I would be tempted to jump board on 2005. But with .NET 1.1 legacy projects lying around, there is just no way we can migrate to 2005 yet.
By the way, wiping an old Visual Studio 2005 Beta or CTP version is a nightmare (you are expected to manually uninstall up to 23 components in the correct order)! Luckily Dan Fernandez helped out with the Pre-RTM Visual Studio 2005 Automatic Uninstall Tool.
Thursday, November 03, 2005
J2EE Inhouse Frameworks
Spring Framework lead developers Rod Johnson and Juergen Hoeller have their own opinion about J2EE Inhouse Frameworks (taken from their JavaOne 2005 presentation):


Tuesday, November 01, 2005
In The Kingdom Of The Blind, The One-Eyed Man Is King
Don't you also sometimes wonder where all the top-notch developers are gone? As more and more unskilled novices enter the scene while simultaneously some old veterans are losing the edge, chances are there are not too many star programmers left to steer the ship through difficult waters. Not that this is happening everywhere, it's just that it seems to be happening at some of the software shops I know, so I am quite sure the same is true for other places as well...
The combination of newcomers on one hand, who have some theoretical knowledge about new technology, but at the same time no idea how to turn that knowledge into working products, and long-serving developers on the other hand, who are not willing to relearn their profession on each single day, is particularly dangerous.
The greenhorns often load a pile of tech buzzwords upon their more-experienced peers along with poorly engineered, homebrewn frameworks (notwithstanding they might know about third party software platform and component markets, they tend to suffer the Not-Invented-Here Syndrome). After that, they endlessly keep on theorizing whether to favor the Abstract Factory Pattern over the Factory Method Pattern or not.
At the same time their seasoned colleagues - overwhelmed with all that new stuff - just want to turn back time to the good old days when all they had to worry about was whether the Visual Basic interpreter swallowed their code or their mainframe batch jobs produced a valid result. In the kingdom of the blind, the one-eyed man is king.
Really it's weird - the people who are smart AND experienced AND get something done, they seem to be an endangered species. Some of them waft away to middle management (which is often a frustrating experience, as they cannot do any more what they do best), others are still around but because of one reason or another they are not in charge any more of taking the lead on the technology frontier. It's the architecture astronauts who took over. And it's the MBAs who allowed them to. Pity.
The combination of newcomers on one hand, who have some theoretical knowledge about new technology, but at the same time no idea how to turn that knowledge into working products, and long-serving developers on the other hand, who are not willing to relearn their profession on each single day, is particularly dangerous.
The greenhorns often load a pile of tech buzzwords upon their more-experienced peers along with poorly engineered, homebrewn frameworks (notwithstanding they might know about third party software platform and component markets, they tend to suffer the Not-Invented-Here Syndrome). After that, they endlessly keep on theorizing whether to favor the Abstract Factory Pattern over the Factory Method Pattern or not.
At the same time their seasoned colleagues - overwhelmed with all that new stuff - just want to turn back time to the good old days when all they had to worry about was whether the Visual Basic interpreter swallowed their code or their mainframe batch jobs produced a valid result. In the kingdom of the blind, the one-eyed man is king.
Really it's weird - the people who are smart AND experienced AND get something done, they seem to be an endangered species. Some of them waft away to middle management (which is often a frustrating experience, as they cannot do any more what they do best), others are still around but because of one reason or another they are not in charge any more of taking the lead on the technology frontier. It's the architecture astronauts who took over. And it's the MBAs who allowed them to. Pity.
Wednesday, October 26, 2005
PDC05 Sessions Online
In case you - just like me - were unable to attend the PDC05, Microsoft now put all sessions online including streaming and downloadable presentation videos, transcripts and PowerPoint slides.
Sunday, October 23, 2005
Correlated Subqueries
Just last week we faced a SQL performance issue in one of our applications during ongoing development work. Reason was a correlated subquery - that is, a query that can't be evaluated independently, but depends on the outer query for its results, something like:
or
Please note that those are just examples for better understanding, and that database optimizers can do a better job on simple subqueries like that. Our real-life SQL included several inserts-by-select and a deletes-by-select with inverse exists / not exists operations on complex subqueries.
I know correlated subqueries are unavoidable sometimes, but often there are alternatives. In many cases they can be replaced by joins (which might be or not be faster - e.g. there are situations when exists/not exists-operators are superior to joins, because the database will stop looping as soon as one row is found - but that of course depends on the underlying data). Incoherent subqueries though (in opposite to correlated subqueries) should also outperform joins under normal circumstances.
SQL Server Pro Robert Vieira writes in "Professional SQL Server 2000 Programming": "Internally, a correlated subquery is going to create a nested loop situation. This can create quite a bit of overhead. Subqueries are substantially faster than cursors in most instances, but slower than other options that might be available."
When joining is no option, it might be a good idea to take a step back and do some redesign in a larger context. We managed to achieve a many-fold performance boost on a typical workload by replacing the correlated subqueries with a different approach that produced the same results at the end.
Do not expect the database engine to optimize away all tradeoffs that might be caused by a certain query design. The most-advanced optimizer can't take over complete responsibility from the developer. It's important to be conscious about which kind of tuning your database can do during execution, and which not. Creating an index on the correlated subquery's attribute that connects it to the embedding query is a good starting point.
select A1,
(select min(B1)
from TableB
where TableB.B2 = TableA.A2) as MinB1
from TableAor
select A1
from TableA
where exists (select 1
from TableB
where TableB.B2 = TableA.A2)Please note that those are just examples for better understanding, and that database optimizers can do a better job on simple subqueries like that. Our real-life SQL included several inserts-by-select and a deletes-by-select with inverse exists / not exists operations on complex subqueries.
I know correlated subqueries are unavoidable sometimes, but often there are alternatives. In many cases they can be replaced by joins (which might be or not be faster - e.g. there are situations when exists/not exists-operators are superior to joins, because the database will stop looping as soon as one row is found - but that of course depends on the underlying data). Incoherent subqueries though (in opposite to correlated subqueries) should also outperform joins under normal circumstances.
SQL Server Pro Robert Vieira writes in "Professional SQL Server 2000 Programming": "Internally, a correlated subquery is going to create a nested loop situation. This can create quite a bit of overhead. Subqueries are substantially faster than cursors in most instances, but slower than other options that might be available."
When joining is no option, it might be a good idea to take a step back and do some redesign in a larger context. We managed to achieve a many-fold performance boost on a typical workload by replacing the correlated subqueries with a different approach that produced the same results at the end.
Do not expect the database engine to optimize away all tradeoffs that might be caused by a certain query design. The most-advanced optimizer can't take over complete responsibility from the developer. It's important to be conscious about which kind of tuning your database can do during execution, and which not. Creating an index on the correlated subquery's attribute that connects it to the embedding query is a good starting point.
Sunday, October 16, 2005
So, The Internet Started In 1995?
Maybe I am just to harsh on IT journalism or people writing about technical issues they just don't understand, but sometimes popular scientific articles are simply so far away from the truth, it drives me crazy. This also makes you wonder about all other kind of popular scientific publishing. I know about software, and most popular software articles are plain nonsense. That is were I notice. But what about topics regarding medicine, biology or physics? Is the same happening there as well?
E.g. Dan Brown's book Digital Fortress was cheered by the press, but littered with nonsense each time it came to talk about cryptographic issues.
Today, Austrian Broadcasting Corporation's tech portal ORF Futurezone published an article about the history of the Internet, stating that "Europe accepted TCP/IP and the Internet architecture in 1995" and "the ISO/OSI committees and telephone companies were opposing TCP/IP, as the were favoring the ISO/OSI networking model". You can't be serious! I mean I understand the average Internet user today might think the Internet started in the mid-90's with the first graphical browsers Mosaic (1993) and Netscape (1994), but IT journalists should know better.
Error in reasoning #1: Defining the Internet equal to the World Wide Web. One might argue that the WWW took off in 1994 with the first graphical browsers available on widespread operating systems like Windows 3 or MacOS. But WWW was and is just a subset of Internet protocol standards (mainly HTTP and HTML) and some server and browser implementations. When I took Internet classes at university in 1994, WWW was mentioned as one of several appliances next to Gopher, FTP, Mail, Usenet, Archie, WAIS and the like. In 1992 when I connected to the Internet for the first time, I did so to read Usenet. Predecessor network ARPANet had been introduced in 1969, and soon after the first mails were sent and files were transferred.
Error in reasoning #2: Putting ISO/OSI network model and TCP/IP in conflict. A short answer to that one: The ISO/OSI is a model for network protocol classification, TCP/IP is a concrete network protocol standard and implementationm where TCP is located at ISO/OSI layer 4 (transport layer), and IP at layer 3 (network layer).
Error in reasoning #3: Taking one interviewee's word for granted that there was European opposition (e.g. telephone companies) to the Internet and TCP/IP until 1995. Truth is: Norway was the first European country to connect its research institutions to the ARPANet already in 1973. Austria followed quite late, and joined NSFNet in 1989. The first commercial providers in Austria were founded in the early 90's, when the Internet was opened for commercial usage. If there was opposition from telephone companies, that was true for the US as well. Bob Taylor, ARPANet project lead, was running against windmills at AT&T for years, because packet-switching just did not fit into their circuit-switching-infested brains.
E.g. Dan Brown's book Digital Fortress was cheered by the press, but littered with nonsense each time it came to talk about cryptographic issues.
Today, Austrian Broadcasting Corporation's tech portal ORF Futurezone published an article about the history of the Internet, stating that "Europe accepted TCP/IP and the Internet architecture in 1995" and "the ISO/OSI committees and telephone companies were opposing TCP/IP, as the were favoring the ISO/OSI networking model". You can't be serious! I mean I understand the average Internet user today might think the Internet started in the mid-90's with the first graphical browsers Mosaic (1993) and Netscape (1994), but IT journalists should know better.
Error in reasoning #1: Defining the Internet equal to the World Wide Web. One might argue that the WWW took off in 1994 with the first graphical browsers available on widespread operating systems like Windows 3 or MacOS. But WWW was and is just a subset of Internet protocol standards (mainly HTTP and HTML) and some server and browser implementations. When I took Internet classes at university in 1994, WWW was mentioned as one of several appliances next to Gopher, FTP, Mail, Usenet, Archie, WAIS and the like. In 1992 when I connected to the Internet for the first time, I did so to read Usenet. Predecessor network ARPANet had been introduced in 1969, and soon after the first mails were sent and files were transferred.
Error in reasoning #2: Putting ISO/OSI network model and TCP/IP in conflict. A short answer to that one: The ISO/OSI is a model for network protocol classification, TCP/IP is a concrete network protocol standard and implementationm where TCP is located at ISO/OSI layer 4 (transport layer), and IP at layer 3 (network layer).
Error in reasoning #3: Taking one interviewee's word for granted that there was European opposition (e.g. telephone companies) to the Internet and TCP/IP until 1995. Truth is: Norway was the first European country to connect its research institutions to the ARPANet already in 1973. Austria followed quite late, and joined NSFNet in 1989. The first commercial providers in Austria were founded in the early 90's, when the Internet was opened for commercial usage. If there was opposition from telephone companies, that was true for the US as well. Bob Taylor, ARPANet project lead, was running against windmills at AT&T for years, because packet-switching just did not fit into their circuit-switching-infested brains.
Saturday, October 08, 2005
New Office 12 User Interface
Revolutionary news from Microsoft - Office usability will never be the same again. Office 12 comes with a completely refurnished user interface. Folks, it was about time! E.g. all Word for Windows releases at least since version 2.0 (1992) essentially followed the same user experience paradigm.
For me the most annoying feature ever were "personalized menus" (you know, only the last recently used menus became visible, so you certainly wouldn't find what you were looking for). That one was introduced in, what was it, Office 2000? And don't let me start moaning about Clippy.
But from what I have seen, Office 12 will be a real step forward. It's a bit risky: just imagine the install base - millions and millions of secretaries who have been ill-conditioned over the last decade in order to find the 1% of overall functionality that they are actually using. But only the bold one wins! Don't let Apple take away all the user interface glory, Microsofties!

For me the most annoying feature ever were "personalized menus" (you know, only the last recently used menus became visible, so you certainly wouldn't find what you were looking for). That one was introduced in, what was it, Office 2000? And don't let me start moaning about Clippy.
But from what I have seen, Office 12 will be a real step forward. It's a bit risky: just imagine the install base - millions and millions of secretaries who have been ill-conditioned over the last decade in order to find the 1% of overall functionality that they are actually using. But only the bold one wins! Don't let Apple take away all the user interface glory, Microsofties!
Monday, October 03, 2005
Five Things Every Win32 Programmer Needs To Know
I was really looking forward to Raymond Chen's PDC talk about "Five Things Every Win32 Programmer Needs To Know" (partly because I was curious which five things he would pick, partly I was wondering whether I would "pass the test" - although I do not really consider myself a Win32 programmer at heart). Unfortunately, Channel 9's hand recording was unviewable because of the shaky picture and the poor audio quality. Luckily Raymond's PDC slides are available on commnet.microsoftpdc.com.
Tuesday, September 27, 2005
Saturday, September 17, 2005
So You Think Visual Basic Is A Wimpy Programming Language?
Yes, hardcore programmers sometimes look down on their Visual Basic counterparts. Aren't those the guys who never have to deal with pointers, dynamic memory allocation and multithreading, and who are writing code in a language that was intended for novices (hence "Beginner's All-purpose Symbolic Instruction Code"). Those who use an interpreter whose roots go back to Microsoft's first product, Altair Basic? Hey, not so fast! I know Java and .NET developers who have no clue about pointers, dynamic memory allocation and multithreading either, and are easily outperformed by VB veterans.
Last week I introduced a Visual Basic programmer to MSXML, and prepared some code samples so she would have something to start with. And it's true, the VB6-syntax is partly bizarre. Let alone the Visual Basic IDE which pops up an error messagebox each time I leave a line of code that does not work yet (although I am sure there should be an option to switch off this annoyance). It also has the same usability charm as back when it was introduced on 16-bit Windows. The API is quite limiting as well, so the first thing I had to do was to import several Win32 functions.
Let's face it, legacy applications done in Visual Basic can turn into a CIO's nightmare. A huge number of little standalone VB applications have emerged during the last fifteen years, fragmenting corporate software infrastructure. VB applications are often hard to maintain because of the lack of structured programming the language enforces, VB6 itself is a dead horse and the migration path to VB.NET is tedious.
Legions of VB programmers are supposed to switch over to VB.NET those days. VB.NET does not have a lot in common with the old platform but some syntax similarities. Not only do those programmers suddenly have to grasp OOP, they must also get to know the .NET framework as well as a completely different IDE. BTW, I really dislike the VB.NET syntax. Just compare the MSDN VB.NET and C# code samples. C# is elegant (thanks to MS distinguished engineer Anders Hejlsberg), while VB.NET is nothing but an ugly hybrid.
Another story comes to my mind: a friend of mine, expert on Linux and embedded systems, once went to work for a new employer. He knew they were doing some stuff in Visual Basic. Then one day someone sent him a Powerpoint file. My friend was wondering what it was all about, as the presentation itself was empty. "No, it's no presentation, it's our codebase", the other guy answered. They had done their stuff in Powerpoint VBA. Unbelievable! Needless to mention, my friend left that company shortly after.
So if you want to know my opinion: Visual Basic might be wimpy, but in some perverted way it's for the real tough as well.
Last week I introduced a Visual Basic programmer to MSXML, and prepared some code samples so she would have something to start with. And it's true, the VB6-syntax is partly bizarre. Let alone the Visual Basic IDE which pops up an error messagebox each time I leave a line of code that does not work yet (although I am sure there should be an option to switch off this annoyance). It also has the same usability charm as back when it was introduced on 16-bit Windows. The API is quite limiting as well, so the first thing I had to do was to import several Win32 functions.
Let's face it, legacy applications done in Visual Basic can turn into a CIO's nightmare. A huge number of little standalone VB applications have emerged during the last fifteen years, fragmenting corporate software infrastructure. VB applications are often hard to maintain because of the lack of structured programming the language enforces, VB6 itself is a dead horse and the migration path to VB.NET is tedious.
Legions of VB programmers are supposed to switch over to VB.NET those days. VB.NET does not have a lot in common with the old platform but some syntax similarities. Not only do those programmers suddenly have to grasp OOP, they must also get to know the .NET framework as well as a completely different IDE. BTW, I really dislike the VB.NET syntax. Just compare the MSDN VB.NET and C# code samples. C# is elegant (thanks to MS distinguished engineer Anders Hejlsberg), while VB.NET is nothing but an ugly hybrid.
Another story comes to my mind: a friend of mine, expert on Linux and embedded systems, once went to work for a new employer. He knew they were doing some stuff in Visual Basic. Then one day someone sent him a Powerpoint file. My friend was wondering what it was all about, as the presentation itself was empty. "No, it's no presentation, it's our codebase", the other guy answered. They had done their stuff in Powerpoint VBA. Unbelievable! Needless to mention, my friend left that company shortly after.
So if you want to know my opinion: Visual Basic might be wimpy, but in some perverted way it's for the real tough as well.
Friday, September 09, 2005
Andy Hertzfeld On NerdTV
Bob Cringely just published the first in series of interviews on NerdTV (hey there is no MPEG-4 codec in Windows Media Player - luckily Quicktime supports MPEG-4). He talks with original Macintosh system software programmer Andy Hertzfeld about Apple, the Mac project, Steve Jobs, Open Source and how he just recently excavated the old sourcecode of Bill Atkinson's MacPaint for Donald Knuth. Today Andy Hertzfeld runs Folklore.Org - "Anecdotes about the development of Apple's original Macintosh computer, and the people who created it".
At one point they refer to Cringely's 1996 TV-series "Triumph Of The Nerds", where Steve Jobs accused Microsoft of having "no taste" (his words actually were "The only problem with Microsoft is they just have no taste, they have absolutely no taste, and what that means is - I don't mean that in a small way I mean that in a big way.").
So after "Triumph Of The Nerds" aired, Steve Jobs came over to Andy Hertzfeld's place, and called Bill Gates to apologize. When Steve Jobs says sorry to Bill Gates, it goes like "Bill I'm calling to apologize. I saw the documentary and I said that you had no taste. Well I shouldn't have said that publicly. It's true, but I shouldn't have said it publicly". And Bill Gates responds saying "Steve, I may have no taste, but that doesn't mean my entire company has no taste". This little episode tells us a lot about those two characters, doesn't it?
At one point they refer to Cringely's 1996 TV-series "Triumph Of The Nerds", where Steve Jobs accused Microsoft of having "no taste" (his words actually were "The only problem with Microsoft is they just have no taste, they have absolutely no taste, and what that means is - I don't mean that in a small way I mean that in a big way.").
So after "Triumph Of The Nerds" aired, Steve Jobs came over to Andy Hertzfeld's place, and called Bill Gates to apologize. When Steve Jobs says sorry to Bill Gates, it goes like "Bill I'm calling to apologize. I saw the documentary and I said that you had no taste. Well I shouldn't have said that publicly. It's true, but I shouldn't have said it publicly". And Bill Gates responds saying "Steve, I may have no taste, but that doesn't mean my entire company has no taste". This little episode tells us a lot about those two characters, doesn't it?
Sunday, September 04, 2005
The Good, The Bad, The Ugly Elevator Panel User Interface
Some days ago, I blogged about the completely-screwed-up user interface of a parking garage ticketmachine here in the city of Linz, Austria. Same place, different usability nightmare: The garage elevator.
I should explain first: There are two parking decks, both under ground. They are labeled "level 1" and "level 2". The elevator stops at both levels, and at the ground floor from where you can exit to the outside.
Anyway, who ever is responsible for this parking garage's elevator panel, did not follow the "Keep-It-Simple-Stupid"-principle (remember, this panel and its "manual" are located outside the cabin):
Translation:
You want to enter the destination floor? [No, do I have to?]
Press "-".
Press "1" or "2".
No further operations required inside the cabin.
It's hard to notice, but the "-"-button is actually in the left bottom corner.
There are only levels 0, 1 and 2 - what are the other buttons good for? Oh I see, future extensability. Once they will excavate a whole new level 3 under ground, at least they won't have to touch the elevator panel! And what for the "-"? There is no "+"-counterpart. It all ends at level 0. This just forces you to press two buttons, instead of one. But then, it's mathematically correct, right?
So, you are standing at the ground floor, and want to go down. Unless you press "-" and then "1" or "2", the cabin will not even show up. Similar when you enter at level 2, you can then either enter "0" or "-" followed by "1". It's just ridiculous!
Now I am sure the Petronas Twin Towers must have a complex shortest-path-selection-algorithm implemented for their elevator system. I understand this decision making can be simplified if the user signals the destination of his journey already when calling the cabin. As we all know, standard elevators provide one up- and one down-button for summoning the cabin, so the cabin only stops if it's passing by in the right direction (not to mention that many people still press the wrong button or both of them once they get impatient). This ought to be enough for small to medium size systems.
Where does that thing want to go anyway? On level 0, basement parking garage customers tend to go down. On the lower levels, they most likely want to get up to the surface. OK, some weirdows might enjoy shuttling between level 1 and 2. Anyway with one and only one intermediate level, there is no real need for a complex path-optimization approach, which would depend on preceding destination input. Knowing whether we want to go up or down, followed by destination input inside the cabin should be the natural choice. Also, that's what people are used to.
I have observed elderly folks standing in front of that panel, giving up and going up or down the stairs by foot. I know this interface overstrains users. But hey, at least there are "no further operations required inside the cabin".
And I have tried, it is not a telephone, either. And in case it's supposed to be a calculator, where is the square root button? (talking about calculators, just a short off-topic-insertion at this point: you might want to have a look at Kraig Brockschmidt's online book "Mystic Microsoft" - Kraig is the creator of the original Windows 1.0 calculator and author of "Inside OLE").
I should explain first: There are two parking decks, both under ground. They are labeled "level 1" and "level 2". The elevator stops at both levels, and at the ground floor from where you can exit to the outside.
Anyway, who ever is responsible for this parking garage's elevator panel, did not follow the "Keep-It-Simple-Stupid"-principle (remember, this panel and its "manual" are located outside the cabin):
 |  |
Translation:
You want to enter the destination floor? [No, do I have to?]
Press "-".
Press "1" or "2".
No further operations required inside the cabin.
It's hard to notice, but the "-"-button is actually in the left bottom corner.
There are only levels 0, 1 and 2 - what are the other buttons good for? Oh I see, future extensability. Once they will excavate a whole new level 3 under ground, at least they won't have to touch the elevator panel! And what for the "-"? There is no "+"-counterpart. It all ends at level 0. This just forces you to press two buttons, instead of one. But then, it's mathematically correct, right?
So, you are standing at the ground floor, and want to go down. Unless you press "-" and then "1" or "2", the cabin will not even show up. Similar when you enter at level 2, you can then either enter "0" or "-" followed by "1". It's just ridiculous!
Now I am sure the Petronas Twin Towers must have a complex shortest-path-selection-algorithm implemented for their elevator system. I understand this decision making can be simplified if the user signals the destination of his journey already when calling the cabin. As we all know, standard elevators provide one up- and one down-button for summoning the cabin, so the cabin only stops if it's passing by in the right direction (not to mention that many people still press the wrong button or both of them once they get impatient). This ought to be enough for small to medium size systems.
Where does that thing want to go anyway? On level 0, basement parking garage customers tend to go down. On the lower levels, they most likely want to get up to the surface. OK, some weirdows might enjoy shuttling between level 1 and 2. Anyway with one and only one intermediate level, there is no real need for a complex path-optimization approach, which would depend on preceding destination input. Knowing whether we want to go up or down, followed by destination input inside the cabin should be the natural choice. Also, that's what people are used to.
I have observed elderly folks standing in front of that panel, giving up and going up or down the stairs by foot. I know this interface overstrains users. But hey, at least there are "no further operations required inside the cabin".
And I have tried, it is not a telephone, either. And in case it's supposed to be a calculator, where is the square root button? (talking about calculators, just a short off-topic-insertion at this point: you might want to have a look at Kraig Brockschmidt's online book "Mystic Microsoft" - Kraig is the creator of the original Windows 1.0 calculator and author of "Inside OLE").
Friday, August 26, 2005
Multiple Inheritance And The "This"-Pointer
Excellent article on why using C++'s <dynamic_cast> is a good idea when casting multiple-inheritance instance pointers (this is true even if you derive from only one concrete class plus one or more pure virtual classes (=interfaces)). <dynamic_cast> is aware of the different vtable- and memberdata-offsets (due to runtime type information), and will move the casted pointer accordingly.
Some C++ developers tend to keep their C-style casting habits, which will introduce fatal flaws into their code. My recommendation: If you haven't done yet, get to know about the four C++ casting operators, and apply them accordingly. Developers should understand the memory layout of their data types. And what a vtable is. And what a compiler can do, and what not.
If still in doubt, use <dynamic_cast> - it's slower, but safe. Don't forget to check whether the cast was successful, though.
Some C++ developers tend to keep their C-style casting habits, which will introduce fatal flaws into their code. My recommendation: If you haven't done yet, get to know about the four C++ casting operators, and apply them accordingly. Developers should understand the memory layout of their data types. And what a vtable is. And what a compiler can do, and what not.
If still in doubt, use <dynamic_cast> - it's slower, but safe. Don't forget to check whether the cast was successful, though.
Thursday, August 18, 2005
How Bill Gates Outmaneuvered Gary Kildall
The History Of Computing Project provides plenty of information on companies and individuals who helped to shape today's computer industry. It includes historical anecdotes and timelines, e.g. a summary of Microsoft's history. What's missing in the 1980/1981 entries (dawn of the IBM PC and DOS) is the story how Bill Gates outmaneuvered Digital Research and Gary Kildall, then leading 8-bit OS vendor with their CP/M system. So here is a summary of what happened. I must have heard / read dozens of slightly different variations on this story over the years, so this outline of events should be pretty accurate:
Back at that time, Microsoft provided programming languages (Basic, Fortran, Cobol and the like) for 8-bit machines, while the most-widespread operating system CP/M came from Digital Research. The two companies had an unspoken agreement on not raiding the other one's market. But Microsoft had licensed CP/M for a very successful hardware product at that time - the so called SoftCard for the Apple II. SoftCard contained a Zilog Z80 processor, and allowed Apple II owners to run CP/M and CP/M applications.
IBM - awakened by Apple's microcomputer success with the Apple II - approached Microsoft in search of an operating system and programming languages for their "Project Chess" = "Acorn" = "IBM PC" machine, which was to be a microcomputer based on open standards and off-the-self parts. Those off-the-self parts included Intel's 8088 CPU, a downsized 8086. One exception was the BIOS chip, which was reverse-engineered later by Compaq and others.
The legend goes that IBM's decision makers mistakenly thought CP/M originated from Microsoft, but that sounds doubtful. Anyway, Bill Gates told IBM they would have to talk to Digital Research, and even organized an appointment with Digital Research CEO Gary Kildall.
Kildall was a brilliant computer scientist, but probably missing the business instinct and restless ambition of Bill Gates. Some people say Gates didn't inform Kildall about who the prospective customer was, but only noted that "those guys are important", which might be plausible, as IBM was paranoid about anyone getting to know what they were doing. On the other hand, Gates himself once mentioned in an interview that Kildall knew it was IBM who was coming.
So the next day some IBM representatives, including IBM veteran Jack Sams, flew from Microsoft's office in Seattle to Pacific Grove, California, where Digital Research was located. When they arrived, Kildall was not there. While Gates later commented that "Gary went flying" (Kildall was a hobbyist pilot), truth is that Kildall had already another meeting scheduled and was visiting important customers, and flew his own plane to get there. Kildall's wife Dorothy McEwen and her lawyer fatally misjudged the situation in the meantime and declined to sign IBM's nondisclosure-agreement, so IBM left with empty hands. It should be noted that Gates had no problem signing a NDA.
Again, different versions exist about that part of the story - one of them goes that Kildall actually appeared in the afternoon, but no agreement was reached either. Another problem at that time was that Digital Research had not even finished CP/M's 16bit 8086-version.
When IBM returned to Microsoft still looking for an operating system, Gates would not neglect that opportunity. Microsoft co-founder Paul Allen knew of a 16-bit CP/M clone named "Quick and Dirty Operating System" (QDOS), written by Tim Paterson of nearby "Seattle Computer Products". Paterson had grown tired of waiting for CP/M-8086, so he had decided to build one on his own. In a matchless deal, Microsoft purchased QDOS for a mere USD 50,000, and transformed it into PC DOS 1.0. IBM had unexclusively licensed DOS, which opened doors for Microsoft to sell MS DOS (back then slightly varying versions) to every PC clonemaker that would come along.
At the same time, Digital Research finally finished their 16-bit CP/M, which was even offered by IBM as an alternative to DOS, but never took off mainly because of pricing reasons (USD 240 for CP/M in comparison to USD 40 for DOS). Thanks to the similarities between DOS and CP/M, CP/M applications were easily ported to DOS as well - sometimes it was enough to change a single byte value in the program's header section.
Back then IBM still believed that even on the microcomputer market, profits would stem from hardware sales, not from software sales (remember they gave operating system and standard applications away for free in order to sell mainframes - software was a by-product). Their next mistake was to open doors to clonemakers thanks to their open-standards approach and their licensing agreement with Microsoft. IBM also paid a high price later during their OS/2 cooperation with then-strengthened Microsoft, when Microsoft suddenly dropped OS/2 in favor of Windows.
Myths entwine around the real events, and a lot of wrong or over-simplified versions are circulating. People tend to forget that Microsoft was quite successful long before the days of DOS, selling their Basic version, which ran on more or less every 8-bit microcomputer. They actually began in 1975 on the famous Altair. And no, Gates and Allen did not start their company in a garage (those were Steve Jobs and Steve Wozniak with Apple), they established Microsoft in Albuquerque, New Mexico - because that was where Altair producer MITS had its headquarters. Some years later they moved back to their hometown Seattle.
One of my college teachers once told us that "IBM came to Seattle to talk to an OS vendor, but those guys were out of town, so they went to Microsoft instead". Isn't the real story so much more amazing than that oversimplified one?
Update 2016: I found this Tom Rolander interview, who actually "went flying with Gary" that fateful day (at 17min 7sec):
In 2015 I held this presentation on the "History of the PC" at Techplauscherl in Linz:
|
| ||||


Back at that time, Microsoft provided programming languages (Basic, Fortran, Cobol and the like) for 8-bit machines, while the most-widespread operating system CP/M came from Digital Research. The two companies had an unspoken agreement on not raiding the other one's market. But Microsoft had licensed CP/M for a very successful hardware product at that time - the so called SoftCard for the Apple II. SoftCard contained a Zilog Z80 processor, and allowed Apple II owners to run CP/M and CP/M applications.
IBM - awakened by Apple's microcomputer success with the Apple II - approached Microsoft in search of an operating system and programming languages for their "Project Chess" = "Acorn" = "IBM PC" machine, which was to be a microcomputer based on open standards and off-the-self parts. Those off-the-self parts included Intel's 8088 CPU, a downsized 8086. One exception was the BIOS chip, which was reverse-engineered later by Compaq and others.
The legend goes that IBM's decision makers mistakenly thought CP/M originated from Microsoft, but that sounds doubtful. Anyway, Bill Gates told IBM they would have to talk to Digital Research, and even organized an appointment with Digital Research CEO Gary Kildall.
Kildall was a brilliant computer scientist, but probably missing the business instinct and restless ambition of Bill Gates. Some people say Gates didn't inform Kildall about who the prospective customer was, but only noted that "those guys are important", which might be plausible, as IBM was paranoid about anyone getting to know what they were doing. On the other hand, Gates himself once mentioned in an interview that Kildall knew it was IBM who was coming.
 |
| Digital Research's former headquarters, Pacific Grove, California |
Again, different versions exist about that part of the story - one of them goes that Kildall actually appeared in the afternoon, but no agreement was reached either. Another problem at that time was that Digital Research had not even finished CP/M's 16bit 8086-version.
When IBM returned to Microsoft still looking for an operating system, Gates would not neglect that opportunity. Microsoft co-founder Paul Allen knew of a 16-bit CP/M clone named "Quick and Dirty Operating System" (QDOS), written by Tim Paterson of nearby "Seattle Computer Products". Paterson had grown tired of waiting for CP/M-8086, so he had decided to build one on his own. In a matchless deal, Microsoft purchased QDOS for a mere USD 50,000, and transformed it into PC DOS 1.0. IBM had unexclusively licensed DOS, which opened doors for Microsoft to sell MS DOS (back then slightly varying versions) to every PC clonemaker that would come along.
At the same time, Digital Research finally finished their 16-bit CP/M, which was even offered by IBM as an alternative to DOS, but never took off mainly because of pricing reasons (USD 240 for CP/M in comparison to USD 40 for DOS). Thanks to the similarities between DOS and CP/M, CP/M applications were easily ported to DOS as well - sometimes it was enough to change a single byte value in the program's header section.
Back then IBM still believed that even on the microcomputer market, profits would stem from hardware sales, not from software sales (remember they gave operating system and standard applications away for free in order to sell mainframes - software was a by-product). Their next mistake was to open doors to clonemakers thanks to their open-standards approach and their licensing agreement with Microsoft. IBM also paid a high price later during their OS/2 cooperation with then-strengthened Microsoft, when Microsoft suddenly dropped OS/2 in favor of Windows.
Myths entwine around the real events, and a lot of wrong or over-simplified versions are circulating. People tend to forget that Microsoft was quite successful long before the days of DOS, selling their Basic version, which ran on more or less every 8-bit microcomputer. They actually began in 1975 on the famous Altair. And no, Gates and Allen did not start their company in a garage (those were Steve Jobs and Steve Wozniak with Apple), they established Microsoft in Albuquerque, New Mexico - because that was where Altair producer MITS had its headquarters. Some years later they moved back to their hometown Seattle.
One of my college teachers once told us that "IBM came to Seattle to talk to an OS vendor, but those guys were out of town, so they went to Microsoft instead". Isn't the real story so much more amazing than that oversimplified one?
Update 2016: I found this Tom Rolander interview, who actually "went flying with Gary" that fateful day (at 17min 7sec):
In 2015 I held this presentation on the "History of the PC" at Techplauscherl in Linz:
Sunday, August 14, 2005
The Good, The Bad, The Ugly Ticketmachine User Interface
When visiting my wife in hospital last week, I received an impression of several inner city parking garages. One of them drew my attention thanks to its quite unique ticket issuing machine:

An unused display, several ugly stickers, partly crossed out, redundant labels and arrows, so that even after passing the garage entrance several times I still could not find the ticket button immediately. Regarding the emergency button (="Notruf" in German), I wonder which kind of emergency one might be facing at this point anyway (but maybe a nervous visual overload attack).
Why on earth, if all of that could be so easy:
BTW, this garage has additional bad user experience to offer (hint: calculator-like elevator button panel, so what about pressing "-" and "1" when going to the basement?) - more on that in one of my next postings.

An unused display, several ugly stickers, partly crossed out, redundant labels and arrows, so that even after passing the garage entrance several times I still could not find the ticket button immediately. Regarding the emergency button (="Notruf" in German), I wonder which kind of emergency one might be facing at this point anyway (but maybe a nervous visual overload attack).
Why on earth, if all of that could be so easy:
| ||
|



{kind=link}
BTW, this garage has additional bad user experience to offer (hint: calculator-like elevator button panel, so what about pressing "-" and "1" when going to the basement?) - more on that in one of my next postings.
.NET 2.0: Nullable ValueTypes
Finally they are here: .NET 2.0 introduces Nullable ValueTypes (and a lot more than that - e.g. Generics). What a relief - it was kind of tedious having to implement our own nullable DateTime- or GUID-wrappers, just because those attributes happened to be nullable on the database as well, or because you wanted to pass null-values in case of strongly typed method parameters.
Friday, August 05, 2005
Agile Programming
"Are you doing XP-style unit testing throughout your project? You know, we even write the test code prior to the functional code on each and every method.", the recent hire (fresh from polytechnic school) insisted. "Leave me in peace", I said to myself, "I have real work to do". Two years later I asked him how he was doing. "You know we gave up on the eXtreme Programming approach. It just was frustrating. Oh, and our project was cancelled"
Please don't get me wrong, XP brought some exciting new ideas, and I really admire Kent Beck for the groundwork he has laid in this area. XP also shares several ideas with the proposal I will discuss in a moment. I just don't understand people who immediately jump on the bandwagon of the latest software methodology hype, each time something new comes along. Those folks don't act deliberately, they don't consider whether certain measures make or do not make sense in a specific project scenario, they don't challenge new approaches, they just blindly follow them. Why? I am not sure, but my theory goes that forcing their favorite methodology on other people within their tiny software development microcosm creates a boost on their low self-esteem.
So I am not going to force my favorite methodology on you. But maybe you are also tired of overly bureaucratic software engineering (you know, no line of code will be written until hundreds of pages of detailed specs have been approved by several committees), and eXtreme programming is just too, well, extreme for your taste. The proposal that comes closest to what I think software development should be all about is Agile Programming (you might want to have a look at Martin Fowler's excellent introductionary article). In essence, Agile Programming is people-oriented (requires creative and talented people), acknowledges that there is just not a lot of predictability in the process of creating software, and puts emphasis on iterative development and communication with the customer.
Here, your design document IS in your sourcecode. Software development is not like the building industry, that's why you cannot just draw a construction plan and hand it over to the workers (=programmers) for execution. Agile Programming embraces change (e.g. changing requirements - face it, this will always happen), and helps to react accordingly, thus avoiding the rude awakening after months of denial that you project is off track - the kind of awakenings that might happen as long as you can hide behind stacks of UML diagrams and project plans, but do not have to deliver a new software release each week.
There is not "One-Size-Fits-All", and I probably wouldn't use Agile Programming when building navigation software for the NASA. But many of the agile principles just make sense within the projects I work on (and I try to apply those principles selectively).
I also don't completely agree to the Agile Manifesto's statement #1 "We have come to value individuals and interactions over processes and tools". If they would just have left away the part about tools, it would have been fine. I know what they meant, though, but let me be picky this time. Tools are important. Thing is, smart individuals tend to use or create good tools, so it all comes together again at the end. The manifesto also continues "That is, while there is value in the items on the right [referring to processes and tools], we value the items on the left [referring to individuals and interactions] more". Unfortunately people often forget about the footnotes, and might interpretate this more in a sense of "it doesn't matter I use Edlin for programming, as long as I write clever code".
Changing topic, did you know that Microsoft Project was tailored for building industry projects, NOT for software projects? Think about it for a moment.
Please don't get me wrong, XP brought some exciting new ideas, and I really admire Kent Beck for the groundwork he has laid in this area. XP also shares several ideas with the proposal I will discuss in a moment. I just don't understand people who immediately jump on the bandwagon of the latest software methodology hype, each time something new comes along. Those folks don't act deliberately, they don't consider whether certain measures make or do not make sense in a specific project scenario, they don't challenge new approaches, they just blindly follow them. Why? I am not sure, but my theory goes that forcing their favorite methodology on other people within their tiny software development microcosm creates a boost on their low self-esteem.
So I am not going to force my favorite methodology on you. But maybe you are also tired of overly bureaucratic software engineering (you know, no line of code will be written until hundreds of pages of detailed specs have been approved by several committees), and eXtreme programming is just too, well, extreme for your taste. The proposal that comes closest to what I think software development should be all about is Agile Programming (you might want to have a look at Martin Fowler's excellent introductionary article). In essence, Agile Programming is people-oriented (requires creative and talented people), acknowledges that there is just not a lot of predictability in the process of creating software, and puts emphasis on iterative development and communication with the customer.
Here, your design document IS in your sourcecode. Software development is not like the building industry, that's why you cannot just draw a construction plan and hand it over to the workers (=programmers) for execution. Agile Programming embraces change (e.g. changing requirements - face it, this will always happen), and helps to react accordingly, thus avoiding the rude awakening after months of denial that you project is off track - the kind of awakenings that might happen as long as you can hide behind stacks of UML diagrams and project plans, but do not have to deliver a new software release each week.
There is not "One-Size-Fits-All", and I probably wouldn't use Agile Programming when building navigation software for the NASA. But many of the agile principles just make sense within the projects I work on (and I try to apply those principles selectively).
I also don't completely agree to the Agile Manifesto's statement #1 "We have come to value individuals and interactions over processes and tools". If they would just have left away the part about tools, it would have been fine. I know what they meant, though, but let me be picky this time. Tools are important. Thing is, smart individuals tend to use or create good tools, so it all comes together again at the end. The manifesto also continues "That is, while there is value in the items on the right [referring to processes and tools], we value the items on the left [referring to individuals and interactions] more". Unfortunately people often forget about the footnotes, and might interpretate this more in a sense of "it doesn't matter I use Edlin for programming, as long as I write clever code".
Changing topic, did you know that Microsoft Project was tailored for building industry projects, NOT for software projects? Think about it for a moment.
Wednesday, August 03, 2005
Stop The Hype About Webservices
Michael Nascimento takes the same line as me a couple of days ago...
Tuesday, August 02, 2005
Marcin Wichary's User Interface Gallery
One of the most complete user interface collections I have ever seen: Marcin Wichary's GUIdebook. Great stuff, e.g. Windows 1.0 screenshots or the complete Macintosh Introduction Advertising Campaign. By the way, Marcin is looking for a new ISP, I am sure there is someone out there willing to support this great project.
DOS Ain't Done 'Til Lotus Won't Run?
Time to straighten out another Microsoft myth: "DOS Ain't Done 'Til Lotus Won't Run" refers to the legend that Microsoft intentionally had manipulated new versions of DOS in order not to be compatible with then leading spreadsheet application Lotus 1-2-3. Just like the old "640k should be enough for everyone"-story, this one also turned out to be another canard.
Saturday, July 30, 2005
About Webservices
Today's message is really simply. Please consider it, when in doubt whether to apply webservices or not:
"Webservices are for integration, not for inter-tier distribution."
This also goes to all .NET and Java consultants out there, who like to present one-click webservice-creation in VS.NET or WSAD: Please don't forget to remind your audience about it. I know that some of you didn't, that's why a lot of people who want to place the webservice-badge on their intranet application now put their whole business layer behind webservices (instead of EJBs (over RMI/IIOP) resp. COM+ services (over DCOM), or no distribution at all using a simple business facade and plain DTOs, or whatever other better-suited solution).
Webservice PROs and CONs
(+) Interoperability between various software applications running on different platforms and/or locations.
(+) Enforces open standards and protocols.
(+) HTTP will go through firewalls with standard filtering rules.
(+) Enables loose coupling (when using Document- instead of RPC-style resp. XML extensibility).
(-) Features such as transactions are either nonexistent or still in their infancy compared to more mature distributed computing standards such as RMI, CORBA, or DCOM.
(-) Poor performance in comparison to other approaches (lower network throughput because of text-based data, XML parsing / transformation required).
This implies: When there is no need for platform interop and firewall pass-through, but for things like high performance and transaction monitoring, don't use webservices as your main business layer protocol. You can still selectively publish webservices to the outside world, which may then call into your business layer (J2EE and COM+ offer direct support on that, e.g. direct mapping to Enterprise Service facades resp. Session Bean facades). But if it's just your intranet client or your web application calling into your business layer, please don't let each call run through the complete SOAP stack.
Things can get even worse than that: Because more and more people practice senseless and blind technology-overuse, there is a project out there where report layouts are being downloaded to the client embedded in .NET assemblies marshalled as byte-arrays over webservices, all of this within one corporate network (where there is no need for interoperability (all is done in .NET) nor HTTP). No kidding. This is for real.
"Webservices are for integration, not for inter-tier distribution."
This also goes to all .NET and Java consultants out there, who like to present one-click webservice-creation in VS.NET or WSAD: Please don't forget to remind your audience about it. I know that some of you didn't, that's why a lot of people who want to place the webservice-badge on their intranet application now put their whole business layer behind webservices (instead of EJBs (over RMI/IIOP) resp. COM+ services (over DCOM), or no distribution at all using a simple business facade and plain DTOs, or whatever other better-suited solution).
Webservice PROs and CONs
(+) Interoperability between various software applications running on different platforms and/or locations.
(+) Enforces open standards and protocols.
(+) HTTP will go through firewalls with standard filtering rules.
(+) Enables loose coupling (when using Document- instead of RPC-style resp. XML extensibility).
(-) Features such as transactions are either nonexistent or still in their infancy compared to more mature distributed computing standards such as RMI, CORBA, or DCOM.
(-) Poor performance in comparison to other approaches (lower network throughput because of text-based data, XML parsing / transformation required).
This implies: When there is no need for platform interop and firewall pass-through, but for things like high performance and transaction monitoring, don't use webservices as your main business layer protocol. You can still selectively publish webservices to the outside world, which may then call into your business layer (J2EE and COM+ offer direct support on that, e.g. direct mapping to Enterprise Service facades resp. Session Bean facades). But if it's just your intranet client or your web application calling into your business layer, please don't let each call run through the complete SOAP stack.
Things can get even worse than that: Because more and more people practice senseless and blind technology-overuse, there is a project out there where report layouts are being downloaded to the client embedded in .NET assemblies marshalled as byte-arrays over webservices, all of this within one corporate network (where there is no need for interoperability (all is done in .NET) nor HTTP). No kidding. This is for real.
Tuesday, July 26, 2005
Please, Do Not String-Concatenate SQL-Parameters
No reason to be surprised that code like this one not only exists in old legacy applications, but also still is being produced on a daily basis - as long one of the most widespread German .NET developer magazines publishes articles like that:
Sonderzeichen in SQL-Kommandos unter ADO.NET
INSERT Murks? Möglicherweise haben Sie es noch gar nicht bemerkt, aber wenn Sie mithilfe von SQL-Anweisungen Texte in Datenbanken eintragen, spielt deren Zusammensetzung eine entscheidende Rolle. Bestimmte Sonderzeichen verwirren ADO.NET, und der SQL-Aufruf kann scheitern. Mit einem einfachen Trick sichern Sie sich ab.
The author then suggests a string-replacement approach in order to manually escape apostrophs when using ADO.NET'S SQLServer Provider. For those of you who are interested, a single ' will be escaped to '' (SQLServer's usual escaping schema for apostrophs).
So he argues apostrophs might brake SQL statements, e.g. on statements like this:
and instead recommends something like:
Now if
Here is how developers with some common sense (as opposed to overpaid consultants who have no idea about real-life projects) are going to handle that: Obviously we prefer to externalize out SQL-code somewhere else, e.g. in our own XML-structure, and embed that XML-file in our assembly. We won't leave SQL lying inside C# code, so we will never even feel the urge to merge those two. And we keep our hands off VS.NET's SQL Query wizard - it just produces unreadable and unmaintainable code. We don't really need a wizard to assemble SQLs, now do we? (if we would, we'd better better get back to Access). And of course, and this is the main point here, we take advantage of parameter placeholders, so ADO.NET will take care of expanding them properly into the statement (and SQLServer will receive the strongly typed values and at the same time can prevent SQL injection) .
How was our expert here going to insert DataTime values (which format pattern to use?), or GUIDs, or BLOBS, or... and with is string-concatenation approach he opens all doors for SQL-injection. Plus he locks in on specific SQLServer collation settings (they'd better never change in the future).
So please, don't bother with solutions for problems that don't even exist.
Sonderzeichen in SQL-Kommandos unter ADO.NET
INSERT Murks? Möglicherweise haben Sie es noch gar nicht bemerkt, aber wenn Sie mithilfe von SQL-Anweisungen Texte in Datenbanken eintragen, spielt deren Zusammensetzung eine entscheidende Rolle. Bestimmte Sonderzeichen verwirren ADO.NET, und der SQL-Aufruf kann scheitern. Mit einem einfachen Trick sichern Sie sich ab.
The author then suggests a string-replacement approach in order to manually escape apostrophs when using ADO.NET'S SQLServer Provider. For those of you who are interested, a single ' will be escaped to '' (SQLServer's usual escaping schema for apostrophs).
So he argues apostrophs might brake SQL statements, e.g. on statements like this:
string sql = "select * from dotnet_authors where clue > 0 or name <> '" + yournamegoeshere + "'";and instead recommends something like:
string sql = "select * from dotnet_authors where clue > 0 or name <> '" + MyCoolEscapingMethod(yournamegoeshere) + "'";Now if
yournamegoeshere contains an apostroph, yes the former command will fail. But who on earth would voluntarily code SQL like this anyway?Here is how developers with some common sense (as opposed to overpaid consultants who have no idea about real-life projects) are going to handle that: Obviously we prefer to externalize out SQL-code somewhere else, e.g. in our own XML-structure, and embed that XML-file in our assembly. We won't leave SQL lying inside C# code, so we will never even feel the urge to merge those two. And we keep our hands off VS.NET's SQL Query wizard - it just produces unreadable and unmaintainable code. We don't really need a wizard to assemble SQLs, now do we? (if we would, we'd better better get back to Access). And of course, and this is the main point here, we take advantage of parameter placeholders, so ADO.NET will take care of expanding them properly into the statement (and SQLServer will receive the strongly typed values and at the same time can prevent SQL injection) .
<sql><![CDATA[
select * from dotnet_authors where clue > 0 or name <> @yournamegoeshere
]]></sql>How was our expert here going to insert DataTime values (which format pattern to use?), or GUIDs, or BLOBS, or... and with is string-concatenation approach he opens all doors for SQL-injection. Plus he locks in on specific SQLServer collation settings (they'd better never change in the future).
So please, don't bother with solutions for problems that don't even exist.
EBay, What Have You Done?
As you certainly know, decimal delimiters and thousand separators differ depending on locale settings. While US-Americans expect something like this
USD 1,000.00
... on a German locale, the same amount is formatted like that
USD 1.000,00
Fair enough. One might expect that EBay is capable of handling those little local differences on their global marketplace. BUT THEY DON'T! In their opinion
USD 49,99
USD 20,00
USD 10,00
... adds up to:
USD 1.069,99
If Donald Knuth could only see what people charge for "The Art Of Computer Programming" nowadays. ;-)
Sorry for the poor image quality, all I had around at that time was Microsoft Photoeditor - no idea why it thinks it has to dither solid color image data.
Reminds me of one former colleague who insisted on writing the decimal value formatter and parser for our monetary input fields (he claimed to have experience from his previous work on ATM terminals - good lord!). If you tabbed through his fields without actually typing something, the value would change (his formatting and parsing algorithms were, well, inconsistent) - e.g. on the first FocusLost from an original input of "10,0" to "100" (?!?) and on the next FocusLost further to "100.00". Looked funny, but just as long as no customer would ever get to see it. Luckily we got rid of it quite early in the project.
Yes, those were the days of Java 1.0 (before java.text.NumberFormat even existed - if I remember correctly it came along with JDK1.1).
USD 1,000.00
... on a German locale, the same amount is formatted like that
USD 1.000,00
Fair enough. One might expect that EBay is capable of handling those little local differences on their global marketplace. BUT THEY DON'T! In their opinion
USD 49,99
USD 20,00
USD 10,00
... adds up to:
USD 1.069,99
If Donald Knuth could only see what people charge for "The Art Of Computer Programming" nowadays. ;-)
Reminds me of one former colleague who insisted on writing the decimal value formatter and parser for our monetary input fields (he claimed to have experience from his previous work on ATM terminals - good lord!). If you tabbed through his fields without actually typing something, the value would change (his formatting and parsing algorithms were, well, inconsistent) - e.g. on the first FocusLost from an original input of "10,0" to "100" (?!?) and on the next FocusLost further to "100.00". Looked funny, but just as long as no customer would ever get to see it. Luckily we got rid of it quite early in the project.
Yes, those were the days of Java 1.0 (before java.text.NumberFormat even existed - if I remember correctly it came along with JDK1.1).
Monday, July 25, 2005
In Praise Of EJBs
Ted Neward replies to Floyd Marinescu's brief EJB retrospection, and I kind of follow his line of arguments. On the largest web application that I have worked on that included EJBs, we did physically split Web-container and EJB-container, and invoked methods on a lightweight stateful Session Bean's remote interface on each request. All further calls to Session (all of them stateless) and Entity Beans went through local interfaces. Thus, each client session kept its own Session Bean context, and all other EJBs referenced from there on would run in the same address space. So physical distribution happened following this design - and the EJB container would decide which node would actually hold the Session Bean (depending on the current workload).
One common (mis-)perception goes that EJBs are too heavyweight (but then, what does "heavyweight" refer to? The API? Metadata AKA Deployment Descriptors? Runtime overhead?), so specifically the Entity Bean specs have been gone through several stages of modification, particularly in the latest EJB version 3.0. My opinion: those constant changes did more harm than good, more then anything else the discussions around EJB 3.0 created fear, uncertainty and doubt among J2EE developers when it comes to container-managed Entity Beans (CMP EJBs are no rocket science either, and yes, they do scale well - what about your third party O/R mapper?).
I always considered EJB 2.0 a fairly well-balanced approach. The complexity was still manageable, and the developer could always decide whether to go a bean-managed ("do it yourself") or container-managed ("let the container take care of it") way of handling persistence, transaction-management, security and the like.
More than that, EJBs represent a clear guidance of how to architect J2EE applications within the business logic and data access layers (JSP Model 2 completed this on the user interface side). No more self-made infrastructure code, or the need for purchasing arcane third party application server infrastructure platforms or obscure persistence frameworks (it's hard to believe how many software vendors still fall into this trap, just because of their lacking enterprise application know-how, and the "stupidly-follow-the-consultant-piper-who-only-tries-to-sell-his-own-product"-syndrome).
Instead, choose your J2EE vendor (or even free alternatives, like JBoss or OpenEJB), so you can concentrate on building your application logic. There are really cool EJB-oriented IDEs out there (IBM's Websphere Application Developer does a great job here). And there is more than enough literature on EJB patterns and strategies, which should also helpt to limit the risk of doing things fundamentally wrong.
One common (mis-)perception goes that EJBs are too heavyweight (but then, what does "heavyweight" refer to? The API? Metadata AKA Deployment Descriptors? Runtime overhead?), so specifically the Entity Bean specs have been gone through several stages of modification, particularly in the latest EJB version 3.0. My opinion: those constant changes did more harm than good, more then anything else the discussions around EJB 3.0 created fear, uncertainty and doubt among J2EE developers when it comes to container-managed Entity Beans (CMP EJBs are no rocket science either, and yes, they do scale well - what about your third party O/R mapper?).
I always considered EJB 2.0 a fairly well-balanced approach. The complexity was still manageable, and the developer could always decide whether to go a bean-managed ("do it yourself") or container-managed ("let the container take care of it") way of handling persistence, transaction-management, security and the like.
More than that, EJBs represent a clear guidance of how to architect J2EE applications within the business logic and data access layers (JSP Model 2 completed this on the user interface side). No more self-made infrastructure code, or the need for purchasing arcane third party application server infrastructure platforms or obscure persistence frameworks (it's hard to believe how many software vendors still fall into this trap, just because of their lacking enterprise application know-how, and the "stupidly-follow-the-consultant-piper-who-only-tries-to-sell-his-own-product"-syndrome).
Instead, choose your J2EE vendor (or even free alternatives, like JBoss or OpenEJB), so you can concentrate on building your application logic. There are really cool EJB-oriented IDEs out there (IBM's Websphere Application Developer does a great job here). And there is more than enough literature on EJB patterns and strategies, which should also helpt to limit the risk of doing things fundamentally wrong.
Saturday, July 16, 2005
AJAX Or The Return Of JavaScript
Regarding all that AJAX ("Asynchronous JavaScript and XML") hype that spread around lately (which came along with a new kind of web applications, see GMail, Google Maps, Flickr and the like) I wonder whether server-side gui-event processing (e.g. as propagated by ASP.NET) has come to an end, or if both approaches will co-exist side-by-side in the future. To me, AJAX seems to have some clear advantages on the user-experience level. On the other hand, AJAX denotes an approach, not a standard, so the question arises which AJAX base library to use.
What's interesting to note is that probably the main technology enabler for AJAX was the introduction of the JavaScript XMLHttpRequest class, which originally came from Microsoft (ActiveX's "Microsoft.XMLHTTP"). Mozilla, Safari and other browsers followed with more or less identical implementations. Another proof that - yes indeed - Microsoft DOES innovate.
For me this means to revamp my somewhat dusty JavaScript knowledge (JavaScript 1.2 was were I stopped - enough to do some simple client-side stuff that did not require server round-trips, and was available on all browsers - but certainly not enough for building AJAX applications).
What's interesting to note is that probably the main technology enabler for AJAX was the introduction of the JavaScript XMLHttpRequest class, which originally came from Microsoft (ActiveX's "Microsoft.XMLHTTP"). Mozilla, Safari and other browsers followed with more or less identical implementations. Another proof that - yes indeed - Microsoft DOES innovate.
For me this means to revamp my somewhat dusty JavaScript knowledge (JavaScript 1.2 was were I stopped - enough to do some simple client-side stuff that did not require server round-trips, and was available on all browsers - but certainly not enough for building AJAX applications).
Monday, July 11, 2005
A.K. Has Little Patience...
... with colleagues apparently not at his level of knowledge.
My experience is: while people lacking some qualification might indeed be dreadful to software projects, even worse are the folks who think they know and make their seniors (who are most likely even more clueless) believe so too, hence are then put in charge of things they should better leave their hands off.
I once was shown some old Java code originating from a guy who used to be the organizations' only person with little above zero Java/XML/HTTP-knowledge. He managed to make that Java system Unicode-inapt (now that's a real accomplishment on a platform that is Unicode-able per definition), wrote his own, broken XML-parser/-transformer which produced whatever format but not XML (ignoring the fact that JAXP has been part of the JDK since version 1.3 - the poor maintenance programmes suffered for years to come, as they could not use real XML on the other side of the pipe either), and even implemented his own HTTP on top of TCP sockets (or what would be a poor man's HTTP: writing "GET [someurl]" to a socket stream and reading the response), just because he didn't know how to send HTTP headers using Java's HTTP API (of course a complete HTTP implementation is part of every Java version since 1995). Back then he was the proclaimed Java expert on that very group (as everyone else there was coding VB or whatever), hence was given plenty of rope, and consequently screwed up.
I prefer coworkers who admit they don't know too much about a certain technology, but are willing to learn and to listen. Give them easy tasks at first, support them, and let them grow step by step. Programming is no rocket science, and no brain surgery either. Heck there are so many things even inside my area of expertise that I don't know much of. But I know that I don't know, and I know whom to ask or how to learn when required.
But if A.K.'s colleague is an idiot and not willing to change something about it, I offer my condolences.
My experience is: while people lacking some qualification might indeed be dreadful to software projects, even worse are the folks who think they know and make their seniors (who are most likely even more clueless) believe so too, hence are then put in charge of things they should better leave their hands off.
I once was shown some old Java code originating from a guy who used to be the organizations' only person with little above zero Java/XML/HTTP-knowledge. He managed to make that Java system Unicode-inapt (now that's a real accomplishment on a platform that is Unicode-able per definition), wrote his own, broken XML-parser/-transformer which produced whatever format but not XML (ignoring the fact that JAXP has been part of the JDK since version 1.3 - the poor maintenance programmes suffered for years to come, as they could not use real XML on the other side of the pipe either), and even implemented his own HTTP on top of TCP sockets (or what would be a poor man's HTTP: writing "GET [someurl]" to a socket stream and reading the response), just because he didn't know how to send HTTP headers using Java's HTTP API (of course a complete HTTP implementation is part of every Java version since 1995). Back then he was the proclaimed Java expert on that very group (as everyone else there was coding VB or whatever), hence was given plenty of rope, and consequently screwed up.
I prefer coworkers who admit they don't know too much about a certain technology, but are willing to learn and to listen. Give them easy tasks at first, support them, and let them grow step by step. Programming is no rocket science, and no brain surgery either. Heck there are so many things even inside my area of expertise that I don't know much of. But I know that I don't know, and I know whom to ask or how to learn when required.
But if A.K.'s colleague is an idiot and not willing to change something about it, I offer my condolences.
Bugtracking With Track+
I have been looking for some decent, easy-to-use bugtracking software lately for one of our projects. My first recommondations were Bugzilla and Mantis, simply because I knew them from the past and they were freely available. But their installation procedures (e.g. Perl, MySQL as prerequisites for Bugzilla) overstrained the sysadmin responsible for setting up and maintaining the server (external staff - to his defense, he had no experience in these areas). Plus I never liked Bugzilla's nor Mantis' user interface.
So I continued searching, and finally found Track+. Originally a Sourceforge project, the licensing model was very attractive (free license for up to ten users), the featureset looked good, it supported all kinds of operating systems and databases, and it came with a complete Windows installer. I did a test installation and had it up and running in ten minutes.
The only prerequisite is an existing JDK1.4.2. The setup package also provides Tomcat 5 as web/application container and the free Firebird database. I only had to add tools.jar to Tomcat's classpath (seems as if the installer forgot about that - otherwise Tomcat's JSP engine Jasper would not be able to compile JSP pages).
We will do some more testing and will most likely move our old bugtracking data over to Track+ if it continues to work that smoothly.
So I continued searching, and finally found Track+. Originally a Sourceforge project, the licensing model was very attractive (free license for up to ten users), the featureset looked good, it supported all kinds of operating systems and databases, and it came with a complete Windows installer. I did a test installation and had it up and running in ten minutes.
The only prerequisite is an existing JDK1.4.2. The setup package also provides Tomcat 5 as web/application container and the free Firebird database. I only had to add tools.jar to Tomcat's classpath (seems as if the installer forgot about that - otherwise Tomcat's JSP engine Jasper would not be able to compile JSP pages).
We will do some more testing and will most likely move our old bugtracking data over to Track+ if it continues to work that smoothly.
Tuesday, July 05, 2005
The Next SQL WTF: Where-Unaware Select
Alex Papadimoulis writes: "There was a time where I used to believe that the worst possible way one could retrieve rows from a table was to SELECT the entire table, iterate through the rows, and test a column to see if it matched some critera; ..."
Another infamous SQL WTF: The Where-Unaware Select - woooha, makes me shiver...
By the way, if you think selecting a whole table into memory and scanning through each row programmatically just must be unreal - that's exactly what one of those framework astronauts recommended in a real-life project I know of, where people were forced to use his blasted O/R-mapper. No need to say the project was canceled months later...
Another infamous SQL WTF: The Where-Unaware Select - woooha, makes me shiver...
By the way, if you think selecting a whole table into memory and scanning through each row programmatically just must be unreal - that's exactly what one of those framework astronauts recommended in a real-life project I know of, where people were forced to use his blasted O/R-mapper. No need to say the project was canceled months later...
The Best Software Writing
Today I received my copy of Joel Spolsky's "The Best Software Writing", a collection of software essays (mainly blog articles, hand-selected by the readers of Joel On Software, resp. Joel himself).

I even ordered this book in the States, as it had not been available in Europe at that time. Highly recommended reading material!
I even ordered this book in the States, as it had not been available in Europe at that time. Highly recommended reading material!
Saturday, July 02, 2005
Pragmatic Solutions For An Imperfect World
Some time ago, with only one week to go until the scheduled delivery deadline of our .NET client/server product, our customer reported increasing application instability. My developers had not observed that issue so far, but the application seemed to crash sporadically (but unrepeatably) on our customer's test machines. As we were coding in managed C# only, my first guess was a .NET runtime failure, or a native third party library bug. Luckily, we had installed some post-mortem tracer, which turned out the following exception stacktrace:
Great. Win32 API's PeekMessage() failing, and the failure being mapped to a .NET NullReferenceException. I was starting to get nervous.
I told our customer that our code was not involved (it's always good to be able to blame someone else). But as expected this answer was less-than-satisfying. The end-user couldn't care less about who was guilty, and so did our customer (and they are right to do so). They wanted a solution, and they wanted it fast.
Now I have some faith in Microsoft's implementation of PeekMessage(). It seems to work quite well in general (let's say in all Windows applications that run a message queue) - so something must have been messed up before, with PeekMessage() failing as a result of that. Something running in native code. Something like our report engine (no, it's not Crystal Reports).
We had not invoked our reports too frequently during our normal test runs, as the report layouts and SQL-statements are being done by our customer. So after some report stress testing, those crashes also occurred on our machines. Rarely, but they did. And they occurred asynchronously, within seconds after the last report invocation. Here was the next hint. This was a timing problem, most likely provoked during garbage collection.
So how to prove or disprove this theory? I simply threw all reporting instances into one large ArrayList, so that those would never be picked up by the garbage collector (SIDENOTE: NEVER DO THIS IN A REAL-LIFE PROJECT), and voila: no more crashes, even after hours of stress testing. Obviously keeping all reporting instances in memory introduces a veritable memory leak (still better than a crashing application someone might argue, but this is something I never ever want to see in any implementation I am responsible for). But I had a point of attack: the reporting instances (or one of the objects being referenced by those instances) failed when their Finalizers were invoked.
First of all I noticed that the reporting class (a thin managed .NET wrapper around the reporting engine's native implementation) implemented IDisposable - so I checked all calling code for correct usage (means invocation of Dispose(), most comfortably by applying C#'s "using" construct). When implemented properly, this should prevent a second call to Dispose() during finalization, which might be the root of evil. But our code seemed to be OK.
Next I hard-coded GC.SuppressFinalize() for all reporting instances that had been disposed already, in order to prevent the call to its Destructor (Finalizer in .NET terms) as well, but still no cure - obviously it was not the reporting instance itself that crashed during finalization, but another object referenced by the reporting instance. I ran Lutz Roeder's Reflector, and had a look at all the reporting .NET classes, resp. their Dispose()- and Finalizer-Methods: they only wrapped away native code.
If I could only postpone those Finalizer-calls until as late as necessary (e.g. until free'ing their memory was an absolute must - native resources would not be the problem, as they would be cleaned up long before during the synchronous call to Dispose()). The moment the application would run out of memory even after conventional garbage collection (which might never happen), it would collect the reporting instances. I needed SoftReferences. The garbage collector delays the collection of objects referenced by SoftReferences as long as possible. Unfortunately, .NET does not provide the concept of SoftReferences (Java does, though). .NET has WeakReferences, which will be picked up much earlier than SoftReferences. So I simply started my own background thread, which would remove reporting instances from a static Collection after some minutes of reporting inactivity, hence make them available for garbage collection.
Sometimes luck just strikes me, and that's what happened here: this approach extinguished all sudden crashes. The reporting instances got picked up by the garbage collector (I debugged that), but just a little bit later. Late enough for their finalization to run smoothly. So up to now I don't know the exact cause (as mentioned before, it must have been a timing problem - if reporting instances survive some seconds, they will not crash during finalization). We are still investigating it, and we will find a more suitable fix. But much more important: we shipped on time, and we made our customer happy. All end-user installations are working fine so far.
Do I like the current solution? No, it's a hack. But still it's 10.000 times better than shipping an unstable product. From a certain level of complexity on, all software products contain hacks. Just have a look at the Windows 2000 source (esp. the code comments) that were spread on P2P-networks some time ago. In an imperfect world, you sometimes have to settle with imperfect (but working) solutions for your problems.
Unhandled Exception: System.NullReferenceException: Object reference not set to an instance of an object.
at System.Windows.Forms.UnsafeNativeMethods.PeekMessage(MSG& msg, HandleRef hwnd, Int32 msgMin, Int32 msgMax, Int32 remove)
at System.Windows.Forms.ComponentManager.
System.Windows.Forms.UnsafeNativeMethods+
IMsoComponentManager.FPushMessageLoop
(Int32 dwComponentID, Int32 reason, Int32 pvLoopData)
at System.Windows.Forms.ThreadContext.RunMessageLoopInner(Int32 reason, ApplicationContext context)
at System.Windows.Forms.ThreadContext.RunMessageLoop(Int32 reason, ApplicationContext context)
at System.Windows.Forms.Application.Run(Form mainForm)Great. Win32 API's PeekMessage() failing, and the failure being mapped to a .NET NullReferenceException. I was starting to get nervous.
I told our customer that our code was not involved (it's always good to be able to blame someone else). But as expected this answer was less-than-satisfying. The end-user couldn't care less about who was guilty, and so did our customer (and they are right to do so). They wanted a solution, and they wanted it fast.
Now I have some faith in Microsoft's implementation of PeekMessage(). It seems to work quite well in general (let's say in all Windows applications that run a message queue) - so something must have been messed up before, with PeekMessage() failing as a result of that. Something running in native code. Something like our report engine (no, it's not Crystal Reports).
We had not invoked our reports too frequently during our normal test runs, as the report layouts and SQL-statements are being done by our customer. So after some report stress testing, those crashes also occurred on our machines. Rarely, but they did. And they occurred asynchronously, within seconds after the last report invocation. Here was the next hint. This was a timing problem, most likely provoked during garbage collection.
So how to prove or disprove this theory? I simply threw all reporting instances into one large ArrayList, so that those would never be picked up by the garbage collector (SIDENOTE: NEVER DO THIS IN A REAL-LIFE PROJECT), and voila: no more crashes, even after hours of stress testing. Obviously keeping all reporting instances in memory introduces a veritable memory leak (still better than a crashing application someone might argue, but this is something I never ever want to see in any implementation I am responsible for). But I had a point of attack: the reporting instances (or one of the objects being referenced by those instances) failed when their Finalizers were invoked.
First of all I noticed that the reporting class (a thin managed .NET wrapper around the reporting engine's native implementation) implemented IDisposable - so I checked all calling code for correct usage (means invocation of Dispose(), most comfortably by applying C#'s "using" construct). When implemented properly, this should prevent a second call to Dispose() during finalization, which might be the root of evil. But our code seemed to be OK.
Next I hard-coded GC.SuppressFinalize() for all reporting instances that had been disposed already, in order to prevent the call to its Destructor (Finalizer in .NET terms) as well, but still no cure - obviously it was not the reporting instance itself that crashed during finalization, but another object referenced by the reporting instance. I ran Lutz Roeder's Reflector, and had a look at all the reporting .NET classes, resp. their Dispose()- and Finalizer-Methods: they only wrapped away native code.
If I could only postpone those Finalizer-calls until as late as necessary (e.g. until free'ing their memory was an absolute must - native resources would not be the problem, as they would be cleaned up long before during the synchronous call to Dispose()). The moment the application would run out of memory even after conventional garbage collection (which might never happen), it would collect the reporting instances. I needed SoftReferences. The garbage collector delays the collection of objects referenced by SoftReferences as long as possible. Unfortunately, .NET does not provide the concept of SoftReferences (Java does, though). .NET has WeakReferences, which will be picked up much earlier than SoftReferences. So I simply started my own background thread, which would remove reporting instances from a static Collection after some minutes of reporting inactivity, hence make them available for garbage collection.
Sometimes luck just strikes me, and that's what happened here: this approach extinguished all sudden crashes. The reporting instances got picked up by the garbage collector (I debugged that), but just a little bit later. Late enough for their finalization to run smoothly. So up to now I don't know the exact cause (as mentioned before, it must have been a timing problem - if reporting instances survive some seconds, they will not crash during finalization). We are still investigating it, and we will find a more suitable fix. But much more important: we shipped on time, and we made our customer happy. All end-user installations are working fine so far.
Do I like the current solution? No, it's a hack. But still it's 10.000 times better than shipping an unstable product. From a certain level of complexity on, all software products contain hacks. Just have a look at the Windows 2000 source (esp. the code comments) that were spread on P2P-networks some time ago. In an imperfect world, you sometimes have to settle with imperfect (but working) solutions for your problems.
Tuesday, June 14, 2005
WTF Of The Year
This must be the WTF of the year! Please only look at it when you are mentally prepared. And don't say I didn't warn you: Plain SQL-Code in a browser cookie, executed with DB sysadmin privileges once a certain webpage is visited again. An invitation for SQL-Injection to everyone who happens to know how to type "drop database".
Saturday, June 04, 2005
Saturday, May 21, 2005
HP: Why Not Just Zip Your Printer Driver?
Damn, three large downloads, one hour of wasted time, and my HP Deskjet 3820 still doesn't print thanks to the geniuses at HP who cannot even provide a working driver installation package. The first setup wizard crashes after 10% of unpacking, the second one won't find a DLL function entry point and terminates, and the third one displays an empty frame on my desktop, and that's about it. Go and throw your files and your driver.ini into a zip, would you? I don't need your flashy installer anyway.
Update: Cool, one of the crashing HP driver setup wizards did exactly that - left the driver files laying around in it's working directory. That's what I call customer service. Thank you, HP!
Reminder: Always keep driver CD.
Update: Cool, one of the crashing HP driver setup wizards did exactly that - left the driver files laying around in it's working directory. That's what I call customer service. Thank you, HP!
Reminder: Always keep driver CD.
Friday, May 06, 2005
Don't Surrender To The Technology Pipers
Over and over again non-technical decision makers have screwed up software-projects by blindly following pied pipers propagating their inappropriate technologies. Only in conjunction the clueless suit and the shallow wannabe-techie unfold their destructive powers.
Today, many IT middle and upper management positions are staffed with folks who are technological dinosaurs (the last time they coded was in Basic at highschool, before they stepped out of comp-sci classes when they didn't quite grasp the concept of pointers). Their cluelessness then opens the doors for semi-educated people in the lower ranks, who spent 10 years at college campus playing multiuser dungeon games or others who just went through the federal employment offices' "Becoming a webdesigner in four weeks"-training.
Especially in large corporations this kind of host/parasite-relation happens quite frequently. Some of the species you might encounter:
Framework Astronauts
Here we talk about folks who spend most of their time building application frameworks, that no one on this planet asked for. But that doesn't really matter - the astronaut's goal is to play around with technology, not to produce a valuable product. And without any actual application depending on the framework, there is also no need to maintain backward compatibility, so all the old programming interfaces can be thrown over board each time the astronaut wants to try something new.
Bullshit Pipers
Those people just unload all the latest tech terms on their CEOs, who in change will surrender to the piper's technical superiority. Truth is, the piper has no clue either, most of all he has no practical experience, and he also won't bother to consider the project requirements, as this might make his favorite technology look inappropriate (which it is, of course).
Not-Invented-Here Pilots
They will re-invent the wheel, and write their own database engines, XML-parsers and workflow systems - briefly everything that has been done before by more qualified people, as long as they don't have to work on their real task, namely implementing application logic. My favorite example: proprietary object/relational mappers - right, after all there are no commercial or open source O/R mappers out there, so the only way is to ramp it up on their own.
Some real-life experiences:
A cobbler should stick to his last. I don't pretend to know about networking, so I will not tell our network folks how to configure our routers. And that's why MCSEs should not design software architecture, webdesigners had better leave their hands off enterprise application integration, why Visual Basic programmers can't just switch over to Embedded C++ in a week, and why college hackers might better not single-handedly build up the corporate system infrastructure.
If you want more proof, have a look at The Daily WTF - Curious Perversions In Information Technology. Those things happen each day (believe me, I have seen it) - at a software company close to you.
Today, many IT middle and upper management positions are staffed with folks who are technological dinosaurs (the last time they coded was in Basic at highschool, before they stepped out of comp-sci classes when they didn't quite grasp the concept of pointers). Their cluelessness then opens the doors for semi-educated people in the lower ranks, who spent 10 years at college campus playing multiuser dungeon games or others who just went through the federal employment offices' "Becoming a webdesigner in four weeks"-training.
Especially in large corporations this kind of host/parasite-relation happens quite frequently. Some of the species you might encounter:
Framework Astronauts
Here we talk about folks who spend most of their time building application frameworks, that no one on this planet asked for. But that doesn't really matter - the astronaut's goal is to play around with technology, not to produce a valuable product. And without any actual application depending on the framework, there is also no need to maintain backward compatibility, so all the old programming interfaces can be thrown over board each time the astronaut wants to try something new.
Bullshit Pipers
Those people just unload all the latest tech terms on their CEOs, who in change will surrender to the piper's technical superiority. Truth is, the piper has no clue either, most of all he has no practical experience, and he also won't bother to consider the project requirements, as this might make his favorite technology look inappropriate (which it is, of course).
Not-Invented-Here Pilots
They will re-invent the wheel, and write their own database engines, XML-parsers and workflow systems - briefly everything that has been done before by more qualified people, as long as they don't have to work on their real task, namely implementing application logic. My favorite example: proprietary object/relational mappers - right, after all there are no commercial or open source O/R mappers out there, so the only way is to ramp it up on their own.
Some real-life experiences:
- The consultant who used webservices in every scenario (even for downloading binary data), and designed all of them with the same method signature (input: string, output: string). So much about "service-oriented architecture".
- The integration specialist who parsed huge XML chunks by applying DOM (which loads the whole XML structure into one big in-memory tree), instead of SAX (which is stream-oriented / event-triggered). Of course he found out too late (after deployment on the production servers), so he recommended to split large input-files into several smaller ones each time.
- The self-proclaimed Java architect, who wasted his customer's money by implementing his own (erroneous) HTTP-protocol and XML-parser (which of course exist already as part of the JDK), and managed to deliver a Java application which was not able to handle unicode.
- The programmer who explained that Visual Basic 6 had garbage collection (hint: that's reference counting, not garbage collection, dude).
- The webdesigner who insisted that the casing of his filenames were not important on a Solaris webserver (yes, he came from the Windows world).
- The guy who hand-coded his XSD- and WSDL-files, disregarding the actual implementation, or even broke XML schema syntax rules. Design by (service) contract, anybody?
A cobbler should stick to his last. I don't pretend to know about networking, so I will not tell our network folks how to configure our routers. And that's why MCSEs should not design software architecture, webdesigners had better leave their hands off enterprise application integration, why Visual Basic programmers can't just switch over to Embedded C++ in a week, and why college hackers might better not single-handedly build up the corporate system infrastructure.
If you want more proof, have a look at The Daily WTF - Curious Perversions In Information Technology. Those things happen each day (believe me, I have seen it) - at a software company close to you.
Wednesday, April 27, 2005
Retro Computing: Some Things Just Never Change
Me, in front of my Commodore 128D (1986):

Me, in front of my Commodore 128D (2005):

Me, in front of my Commodore 128D (2005):
Saturday, April 16, 2005
Retro Computing: The Best Joystick Of All Times
Uhhh, I was extremely lucky. Chances were minimal, but I found Suzo's "The Arcade" joystick for 8/16-bit homecomputers on eBay Netherlands. Even better, this turned out to be a "Buy it now"-offer - there was no hesitation for me.

The Arcade was by far not as common as the Quickshot II or the Competition Pro, but there is no other design that fits as comfortably in the palm of my hand. All microswitches, of course. I just spent half an hour playing Soccer II on my C64 using another ancient joystick model, and I constantly hit a misplaced fire button, plus my hand started hurting within minutes.
I can't wait to plug in the Arcade again.
The Arcade was by far not as common as the Quickshot II or the Competition Pro, but there is no other design that fits as comfortably in the palm of my hand. All microswitches, of course. I just spent half an hour playing Soccer II on my C64 using another ancient joystick model, and I constantly hit a misplaced fire button, plus my hand started hurting within minutes.
I can't wait to plug in the Arcade again.
Friday, April 15, 2005
Weirdoz.Org Visual Chat Up And Running Again
Just a short note that the folks at weirdoz.org got their Visual Chat system up and running again.

I developed Visual Chat about eight years ago - those were the days of JDK1.1, Netscape 4.0 and MSIE 4.0 - so please overlook the client's obvious weaknesses. weirdoz.org is now the longest running Visual Chat installation - since 1999 about 300.000 users have signed up.

I developed Visual Chat about eight years ago - those were the days of JDK1.1, Netscape 4.0 and MSIE 4.0 - so please overlook the client's obvious weaknesses. weirdoz.org is now the longest running Visual Chat installation - since 1999 about 300.000 users have signed up.
Wednesday, April 13, 2005
Arno's Software Development Bookshelf
This part of my bookshelf (see below) is all about software development and the software industry. It is slowly starting to outgrow the shelf-space I originally had reserved. I am particularly interested in object oriented design / development (mainly in C++, Java and C#/.NET), application servers, database systems, graphical user interfaces (thin clients and rich clients) and software project management in general. Another fascinating area is the microcomputer revolution, and the history and the legends of silicon valley.
On the other hand, I also try to build up a basic level of knowledge in areas outside my expertise - e.g. I didn't have a a lot of idea about networking in general (one course at university and my little peer-to-peer home LAN just wasn't not enough, and at work networking has always been outside the scope of my tasks). Severals books later I now have something like a global impression of what it is all about (suffice to say that more practical experience is still missing). Same is true for electronics, image editing, game programming, and so on...
Please click on the image in order to zoom in. Some of those books are also listed here, resp. on my Amazon Listmania Lists.

This reminds me that I have to urge some folks to return the following items:
On the other hand, I also try to build up a basic level of knowledge in areas outside my expertise - e.g. I didn't have a a lot of idea about networking in general (one course at university and my little peer-to-peer home LAN just wasn't not enough, and at work networking has always been outside the scope of my tasks). Severals books later I now have something like a global impression of what it is all about (suffice to say that more practical experience is still missing). Same is true for electronics, image editing, game programming, and so on...
Please click on the image in order to zoom in. Some of those books are also listed here, resp. on my Amazon Listmania Lists.

This reminds me that I have to urge some folks to return the following items:
- Harry, I wonder if you will ever finish reading "The Home Computer Wars: An Insider's Account of Commodore and Jack Tramiel". ;-)
- Tommy, who used to work for Xerox in the mid-80s, which is why he was interested in "Dealers of Lightning: Xerox PARC and the Dawn of the Computer Age" and several books about the history of IBM.
- Christoph, who joined my project-team lately, and has a pile of my .NET books and "Professional SQL Server 2000 Programming" lying on his desk - nevermind Christoph, keep them!
- Wolfgang, who wanted to know "Who Says Elephants Can't Dance?".
- Peter, my ally in investigating Apple's share of the "Revolution in The Valley".
Subscribe to:
Posts (Atom)