A while ago we integrated Microsoft Word as an embedded control inside one of our .NET applications. Most tutorials recommend the usage of AxSHDocVw.AxWebBrowser (available from the Visual Studio .NET WinForms designer toolbox), which allows simply to navigate to a file-URL pointing to a Word document. The problem is, AxWebBrowser is nothing else then the well known Internet Explorer webbrowser control, so its behavior depends on the client's internet settings. E.g. when "Confirm open after download" has been set, a file download dialog will appear when programmatically opening an Office document (even in case of a local file), and after confirming the document shows up in a new top-level Word or Excel window, not inside the webbrowser control's host (= your application). That's why we switched from AxWebBrowser to the DSOFramer ActiveX control provided by Microsoft, which doesn't have these restrictions.
Most of the time it's not only required to open Office documents but also to define/manipulate their content, e.g. by replacing form letter placeholders with user data. This can be done by applying Word's COM API. It's a good idea not to let Visual Studio generate COM Interop Assemblies on-the-fly (this generally happens when adding references to COM libraries), but to use Primary Interop Assemblies for Office. Those PIAs can then be redistributed together with the application itself. Note that there are different PIAs for different Office versions, e.g. Office XP and Office 2003. Using Office 2003 features on a client which only got Office XP installed will lead to QueryInterface failures. There are two ways to solve this: (A) develop against the lowest common denominator (e.g. Office XP) or (B) build two Office integration modules with similar functionality, but one of them compiled against Office XP PIAs, and the other one against Office 2003 PIAs. It can then be decided at runtime which of those assemblies to apply, depending on which Office version is available on the client. Hence it's possible to take advantage of Office 2003 features on clients with Office 2003 installed, without breaking Office XP clients. Office 2007 is not out yet, but I suppose the same will be the case there as well.
Follow-Ups:

Saturday, December 30, 2006
Thursday, December 28, 2006
Introduction To The Vanilla Data Access Layer For .NET (Part 2)
Vanilla DAL requires a configuration XML-file for each database to be accessed. The configuration schema definition (XSD) makes it easy to let a tool XML-tools auto-generate the basic element structure:
The sample application comes with the following configuration file.
The configuration file basically tells Vanilla which SQL-statements are available for execution. Every SQL-statement can be logged to stdout by setting the <logsql>-element to true.
Additionally Vanilla supports a simple Dataset-to-DB mapping based on ADO.NET Datasets, with no need to hand-code any SQL at all.
Typically the configuration-file will be compiled into the client's assembly. The ADO.NET connection string can either be specified at runtime (see below), or hard-wired inside the configuration file.
The complete Vanilla DAL API is based on the so called IDBAccessor interface. A tangible IDBAccessor implementation is created by the VanillaFactory at startup time:
Note: SqlServer 2005 Express Edition will install a server instance named (local)\sqlexpress by default.
IDBAccessor is an interface that every database-specific implementation has to support. Working against this interface, the client will never be contaminated with database-specific code. When connecting to another database, all that is required is another configuration file. Multiple configurations can be applied at the same time, simply by instantiating several IDBAccessors.
This is IDBAccessor's current interface (may be subject to change):
At this point Vanilla is ready to go and may execute its first command (which has been declared in the configuration file - see CustomersByCityAndMinOrderCount):
The Datatable is now populated with the query's result.
Alternatively, Vanilla DAL can create select-, insert-, update- and delete-statements on-the-fly in case of a 1:1 mapping between Datatable and database. All that needs to be passed in is a Datatable, which will be filled in case of a select, resp. is supposed to hold data for inserts, updates and deletes:
The advantage of this approach lies in the fact changes of the underlying database schema do not necessarily require manual SQL code adaptation.
Additionally the FillParameter.SchemaHandling property can be applied to define whether the current Datatable schema should be updated by the underlying database schema. By default all columns supported by the Datatable will be fetched from the database (but not more). If there are no Datatable columns, they will be created during runtime. In this case every database column will result in a corresponding column in the Datatable.
Next we will do some in-memory data manipulation, and then update the database accordingly:
RefreshAfterUpdate = true tells Vanilla to issue another select command after the update, which is helpful in case database triggers change data during the process of inserting or updateing, or similar. Auto-increment values set by the database are loaded back to the Dataset automatically.
updateParameter.Locking = UpdateParameter.LockingType.Optimistic will ensure that only those rows are updated which have not been manipulated by someone else in the meantime. Otherwise a VanillaConcurrencyException will be thrown.
At any time, custom SQL code can be executed as well:
To sum up, here is complete sample application:
Part 1 of the Vanilla DAL article series can be found here.
<?xml version="1.0" encoding="utf-8"?>
<xs:schema elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="Config" nillable="true" type="Configuration" />
<xs:complexType name="Configuration">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="1" name="ConnectionString" type="xs:string" />
<xs:element minOccurs="1" maxOccurs="1" name="DatabaseType" type="ConfigDatabaseType" />
<xs:element minOccurs="0" maxOccurs="1" name="LogSql" type="xs:boolean" />
<xs:element minOccurs="0" maxOccurs="1" name="Statements" type="ArrayOfConfigStatement" />
</xs:sequence>
</xs:complexType>
<xs:simpleType name="ConfigDatabaseType">
<xs:restriction base="xs:string">
<xs:enumeration value="Undefined" />
<xs:enumeration value="SQLServer" />
<xs:enumeration value="Oracle" />
<xs:enumeration value="OLEDB" />
</xs:restriction>
</xs:simpleType>
<xs:complexType name="ArrayOfConfigStatement">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="unbounded" name="Statement" nillable="true" type="ConfigStatement" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="ConfigStatement">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="1" name="ID" type="xs:string" />
<xs:element minOccurs="1" maxOccurs="1" name="StatementType" type="ConfigStatementType" />
<xs:element minOccurs="0" maxOccurs="1" name="Code" type="xs:string" />
<xs:element minOccurs="0" maxOccurs="1" name="Parameters" type="ArrayOfConfigParameter" />
</xs:sequence>
</xs:complexType>
<xs:simpleType name="ConfigStatementType">
<xs:restriction base="xs:string">
<xs:enumeration value="Undefined" />
<xs:enumeration value="Text" />
<xs:enumeration value="StoredProcedure" />
</xs:restriction>
</xs:simpleType>
<xs:complexType name="ArrayOfConfigParameter">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="unbounded" name="Parameter" nillable="true" type="ConfigParameter" />
</xs:sequence>
</xs:complexType>
<xs:complexType name="ConfigParameter">
<xs:sequence>
<xs:element minOccurs="0" maxOccurs="1" name="Name" type="xs:string" />
<xs:element minOccurs="1" maxOccurs="1" name="Type" type="ConfigParameterType" />
</xs:sequence>
</xs:complexType>
<xs:simpleType name="ConfigParameterType">
<xs:restriction base="xs:string">
<xs:enumeration value="Undefined" />
<xs:enumeration value="Byte" />
<xs:enumeration value="Int16" />
<xs:enumeration value="Int32" />
<xs:enumeration value="Int64" />
<xs:enumeration value="Double" />
<xs:enumeration value="Boolean" />
<xs:enumeration value="DateTime" />
<xs:enumeration value="String" />
<xs:enumeration value="Guid" />
<xs:enumeration value="Decimal" />
<xs:enumeration value="ByteArray" />
</xs:restriction>
</xs:simpleType>
</xs:schema>
The sample application comes with the following configuration file.
<?xml version="1.0" encoding="UTF-8"?>
<!-- if this is a visual studio embedded resource, recompile project on each change -->
<Config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<DatabaseType>SQLServer</DatabaseType>
<LogSql>true</LogSql>
<!-- Oracle: <DatabaseType>Oracle</DatabaseType> -->
<!-- OLEDB: <DatabaseType>OLEDB</DatabaseType> -->
<Statements>
<Statement>
<StatementType>StoredProcedure</StatementType>
<ID>CustOrderHist</ID>
<Code>
<![CDATA[CustOrderHist]]>
</Code>
<Parameters>
<Parameter>
<Name>customerid</Name>
<Type>String</Type>
</Parameter>
</Parameters>
</Statement>
<Statement>
<StatementType>Text</StatementType>
<ID>CustomersByCityAndMinOrderCount</ID>
<Code><![CDATA[
select *
from customers
where city = @city and
(select count(*) from orders
where orders.customerid = customers.customerid) >=
@minordercount
]]></Code>
<!-- Oracle:
<Code><![CDATA[
select *
from customers
where city = :city and
(select count(*) from orders where orders.customerid =
customers.customerid) >= :minordercount
]]></Code>
-->
<!-- OLEDB:
<Code><![CDATA[
select *
from customers
where city = ? and
(select count(*) from orders where orders.customerid =
customers.customerid) >= ?
]]></Code>
-->
<Parameters>
<Parameter>
<Name>city</Name>
<Type>String</Type>
</Parameter>
<Parameter>
<Name>minordercount</Name>
<Type>Int32</Type>
</Parameter>
</Parameters>
</Statement>
<Statement>
<StatementType>Text</StatementType>
<ID>CustomerCount</ID>
<Code>
<![CDATA[
select count(*)
from customers
]]>
</Code>
<Parameters>
</Parameters>
</Statement>
<Statement>
<StatementType>Text</StatementType>
<ID>DeleteTestCustomers</ID>
<Code>
<![CDATA[
delete
from customers
where companyname like 'Test%'
]]>
</Code>
<Parameters>
</Parameters>
</Statement>
</Statements>
</Config>
The configuration file basically tells Vanilla which SQL-statements are available for execution. Every SQL-statement can be logged to stdout by setting the <logsql>-element to true.
Additionally Vanilla supports a simple Dataset-to-DB mapping based on ADO.NET Datasets, with no need to hand-code any SQL at all.
Typically the configuration-file will be compiled into the client's assembly. The ADO.NET connection string can either be specified at runtime (see below), or hard-wired inside the configuration file.
The complete Vanilla DAL API is based on the so called IDBAccessor interface. A tangible IDBAccessor implementation is created by the VanillaFactory at startup time:
Assembly.GetExecutingAssembly().GetManifestResourceStream(
"VanillaTest.config.xml"),
"Data Source=(local);Initial Catalog=Northwind;
Integrated Security=True");
IDBAccessor accessor = VanillaFactory.CreateDBAccessor(config);
Note: SqlServer 2005 Express Edition will install a server instance named (local)\sqlexpress by default.
IDBAccessor is an interface that every database-specific implementation has to support. Working against this interface, the client will never be contaminated with database-specific code. When connecting to another database, all that is required is another configuration file. Multiple configurations can be applied at the same time, simply by instantiating several IDBAccessors.
This is IDBAccessor's current interface (may be subject to change):
public interface IDBAccessor {
IDbCommand CreateCommand(CommandParameter param);
IDbConnection CreateConnection();
IDbDataAdapter CreateDataAdapter();
void Fill(FillParameter param);
int Update(UpdateParameter param);
int ExecuteNonQuery(NonQueryParameter param);
object ExecuteScalar(ScalarParameter param);
void ExecuteTransaction(TransactionTaskList list);
}
At this point Vanilla is ready to go and may execute its first command (which has been declared in the configuration file - see CustomersByCityAndMinOrderCount):
NorthwindDataset northwindDataset = new NorthwindDataset();
accessor.Fill(new FillParameter(
northwindDataset.Customers,
new Statement("CustomersByCityAndMinOrderCount"),
new ParameterList(
new Parameter("city", "London"),
new Parameter("minordercount", 2)))
);
The Datatable is now populated with the query's result.
Alternatively, Vanilla DAL can create select-, insert-, update- and delete-statements on-the-fly in case of a 1:1 mapping between Datatable and database. All that needs to be passed in is a Datatable, which will be filled in case of a select, resp. is supposed to hold data for inserts, updates and deletes:
northwindDataset.Customers.Clear();
accessor.Fill(new FillParameter(northwindDataset.Customers));
The advantage of this approach lies in the fact changes of the underlying database schema do not necessarily require manual SQL code adaptation.
Additionally the FillParameter.SchemaHandling property can be applied to define whether the current Datatable schema should be updated by the underlying database schema. By default all columns supported by the Datatable will be fetched from the database (but not more). If there are no Datatable columns, they will be created during runtime. In this case every database column will result in a corresponding column in the Datatable.
Next we will do some in-memory data manipulation, and then update the database accordingly:
northwindDataset.Customers.Clear();
accessor.Fill(new FillParameter(northwindDataset.Customers));
foreach (NorthwindDataset.CustomersRow cust1 in
northwindDataset.Customers) {
cust1.City = "New York";
}
UpdateParameter upd1 =
new UpdateParameter(northwindDataset.Customers);
upd1.RefreshAfterUpdate = true;
upd1.Locking = UpdateParameter.LockingType.Optimistic;
accessor.Update(upd1);
RefreshAfterUpdate = true tells Vanilla to issue another select command after the update, which is helpful in case database triggers change data during the process of inserting or updateing, or similar. Auto-increment values set by the database are loaded back to the Dataset automatically.
updateParameter.Locking = UpdateParameter.LockingType.Optimistic will ensure that only those rows are updated which have not been manipulated by someone else in the meantime. Otherwise a VanillaConcurrencyException will be thrown.
At any time, custom SQL code can be executed as well:
Datatable table3 = new Datatable();
ConfigStatement s = new ConfigStatement(ConfigStatementType.Text,
"select * from customers");
accessor.Fill(new FillParameter(
table3,
new Statement(s)));
To sum up, here is complete sample application:
try {
// load db-specific config and instantiate accessor
VanillaConfig config = VanillaConfig.CreateConfig(
Assembly.GetExecutingAssembly().GetManifestResourceStream
("VanillaTest.config.xml"),
"Data Source=(local);Initial Catalog=Northwind;Integrated Security=True");
// SqlServer: "Data Source=(local);Initial Catalog=Northwind;Integrated Security=True"
// SqlServer Express: "Data Source=(local)\\SQLEXPRESS;Initial Catalog=Northwind;Integrated Security=True"
// Oracle: "Server=localhost;User ID=scott;Password=tiger"
// Access: "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=C:\\Program Files\\Microsoft Office\\OFFICE11\\SAMPLES\\Northwind.mdb"
IDBAccessor accessor = VanillaFactory.CreateDBAccessor(config);
// custom statement
NorthwindDataset northwindDataset = new NorthwindDataset();
accessor.Fill(new FillParameter(
northwindDataset.Customers,
new Statement("CustomersByCityAndMinOrderCount"),
new ParameterList(
new Parameter("city", "London"),
new Parameter("minordercount", 2)))
);
// insert data
NorthwindDataset.CustomersRow custIns = northwindDataset.Customers.NewCustomersRow();
custIns.CustomerID = "Foo";
custIns.CompanyName = "Foo";
custIns.City = "New York";
northwindDataset.Customers.AddCustomersRow(custIns);
try
{
accessor.Update(new UpdateParameter(northwindDataset.Customers));
}
catch (VanillaException e)
{
Console.WriteLine(e.Message);
}
// insert and delete data
NorthwindDataset.CustomersRow custDel = northwindDataset.Customers.NewCustomersRow();
custDel.CustomerID = "Foo2";
custDel.CompanyName = "Foo2";
custDel.City = "New York";
northwindDataset.Customers.AddCustomersRow(custDel);
try
{
accessor.Update(new UpdateParameter(northwindDataset.Customers));
custDel.Delete();
accessor.Update(new UpdateParameter(northwindDataset.Customers));
}
catch (VanillaException e)
{
Console.WriteLine(e.Message);
}
// custom statement preprocessed (due to user request)
northwindDataset.Customers.Clear();
ConfigStatement stmt = config.GetStatement("CustomersByCityAndMinOrderCount");
ConfigStatement stmt2 =
new ConfigStatement(stmt.StatementType, stmt.Code + " and 1=1", stmt.Parameters);
accessor.Fill(new FillParameter(
northwindDataset.Customers,
new Statement(stmt2),
new ParameterList(
new Parameter("city", "London"),
new Parameter("minordercount", 2)))
);
// generic statement, this means no sql statement is required (as dataset maps 1:1 to db)
// dataset without schema will receive schema information from db (all columns)
// FillParameter.SchemaHandling allows to apply different schema strategies
DataTable table1 = new DataTable();
accessor.Fill(new FillParameter(table1, "Customers"));
// invoke stored procedure
DataTable table2 = new DataTable();
accessor.Fill(new FillParameter(
table2,
new Statement("CustOrderHist"),
new ParameterList(new Parameter("customerid", "Foo"))));
// hardcoded custom statement (due to user request)
DataTable table3 = new DataTable();
ConfigStatement s = new ConfigStatement(ConfigStatementType.Text, "select * from customers");
accessor.Fill(new FillParameter(
table3,
new Statement(s)));
// simulate a concurrency issue
// fetch the same data twice
northwindDataset.Customers.Clear();
// sql code will be generated on-the-fly, based on the columsn defined in this typed dataset
accessor.Fill(new FillParameter(northwindDataset.Customers, new ParameterList(new Parameter("CustomerID", "Foo"))));
NorthwindDataset northwindDataset2 = new NorthwindDataset();
accessor.Fill(new FillParameter(northwindDataset2.Customers, new ParameterList(new Parameter("CustomerID", "Foo"))));
// write some changes back to db
foreach (NorthwindDataset.CustomersRow cust1 in northwindDataset.Customers)
{
cust1.City = "Paris";
}
UpdateParameter upd1 = new UpdateParameter(northwindDataset.Customers);
upd1.RefreshAfterUpdate = true;
upd1.Locking = UpdateParameter.LockingType.Optimistic;
accessor.Update(upd1);
// try to write some other changes back to db which are now based on wrong original values => concurrency excpetion
foreach (NorthwindDataset.CustomersRow cust in northwindDataset2.Customers) {
cust.City = "Berlin";
}
UpdateParameter upd2 = new UpdateParameter(northwindDataset2.Customers);
upd2.RefreshAfterUpdate = true;
upd2.Locking = UpdateParameter.LockingType.Optimistic;
try {
accessor.Update(upd2);
}
catch (VanillaConcurrencyException e) {
Console.WriteLine(e.Message);
}
// transaction example
northwindDataset.Customers.Clear();
NorthwindDataset.CustomersRow cust2 =
northwindDataset.Customers.NewCustomersRow();
cust2.CustomerID = "TEST1";
cust2.CompanyName = "Tester 1";
northwindDataset.Customers.AddCustomersRow(cust2);
TransactionTaskList list = new TransactionTaskList(
// generic update custom statement
new UpdateTransactionTask(
new UpdateParameter(northwindDataset.Customers)),
// custom statement
new ExecuteNonQueryTransactionTask(
new NonQueryParameter(new Statement("DeleteTestCustomers")))
);
accessor.ExecuteTransaction(list);
Console.WriteLine("VanillaTest completed successfully");
}
catch (VanillaException e) {
Console.WriteLine(e.Message);
}
Console.Write("Press to continue...");
Console.Read();
}
Part 1 of the Vanilla DAL article series can be found here.
Monday, December 11, 2006
Introduction To The Vanilla Data Access Layer For .NET (Part 1)
When I attended a one-week introductory course to .NET back in 2002, the instructor first showed several of Visual Studio's RAD features. He dropped a database table onto a WinForm, which automatically created a typed DataSet plus a ready-to-go DataAdapter, including SQL code. After binding the DataSet to a grid and invoking the DataAdapter's fill-method (one line of hand-written code) the application loaded and displayed database content. My guess is that nearly every .NET developer has seen similar examples.
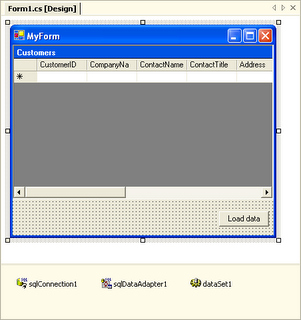 Picture 1: Mixing UI and Data Access Code in Visual Studio .NET
Picture 1: Mixing UI and Data Access Code in Visual Studio .NET
Of course most people will immediately note some drawbacks in this approach. For example, it is not a good idea to have SQL code and database connection strings cluttered all over WinForms or ASP.NET pages. "OK", the .NET instructor will reply at this point, "then don't drop it on a form, drop it on a .NET component class. Make the connection string a dynamic property and bind it to a value in a .config file."
Fair enough. And as a side note I should mention that Visual Studio 2005 has somewhat improved here as well. It won't produce SQL code inside Windows forms any more. Visual Studio 2005 manages project-wide datasources, and places SQL code in so called TableAdapters, which are coupled with the underlying typed DataSet (actually the TableAdapter's code resides in a partial DataSet class file). Whether this is a good idea or not remains questionable.
What has not changed in Visual Studio 2005 is how the SQL query builder works. Once again it looks like a nice feature at first sight, at least if all you want is some straight-forward DataSet-to-Table mapping. In general, query builder is used for editing SQL code embedded in .NET Components. Based on database schema information, it can also auto-generate select-, insert-, update- and delete-statements. Here we can see query builder in action:
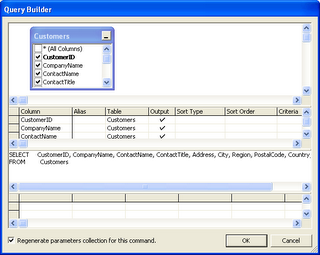 Picture 2: Visual Studio .NET Query Builder
Picture 2: Visual Studio .NET Query Builder
When a DataAdapter has been placed onto a Component's tray, query builder is the only way how to edit the SQL code attached to the DataAdapter's commands, as the SQL code format was certainly not designed for human readability:
 Picture 3: Resulting SQL Code
Picture 3: Resulting SQL Code
It turns out that query builder might not be everybody's tool of choice (maybe with the exception of people with a background in Microsoft Access). Every additional (or removed) database attribute implies code re-generation or manual adaptation. There is no syntax highlighting, no testing capability, and to make things worse, query builder even tries to optimize logical expressions. There are scenarios when query builder definitely changes statement semantics.
ADO.NET is also missing support for database independence. Unlike JDBC and ODBC, which offer completely consistent APIs across all database systems and either are bound to a certain SQL standard or include some semantic extensions in order to address different SQL flavors, ADO.NET providers work in a very vendor-specific manner. While it is true that there exist interface definitions which each provider has to implement (e.g. System.Data.IDbConnection), those interfaces just represent a subset of overall functionality. It should be noted that ADO.NET provider model has improved with .NET 2.0 though.
Arguably there is always the alternative of hand-coding whatever data access feature or convenience function might be missing. But this implies that many people will end up implementing the same things over and over again (e.g. providing a storage system for SQL code, creating parameter-collections, instantiating DataAdapters, commands and connections, opening and closing connections, handling exceptions, managing transactions, encapsulating database-specifics, etc). While there are third party libraries available covering some of these areas many of those products either enforce a completely different programming model and/or involve a steep learning curve. So this is where the Vanilla Data Access Layer for .NET comes in.
Vanilla DAL is a framework for accessing relational databases with ADO.NET. It avoids the problems that RAD-style programming tends to impose, and at the same time helps improving developer productivity.
Features include:
Part 2 of the Vanilla DAL article series can be found here.
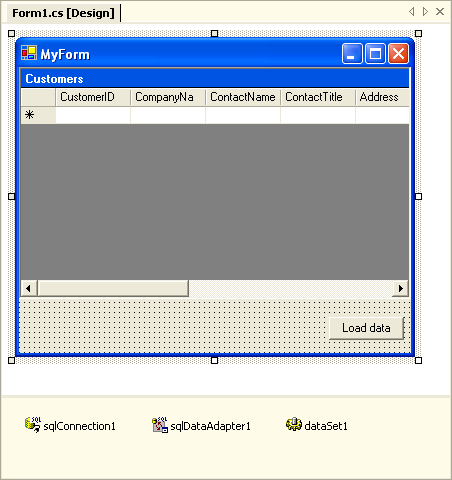 Picture 1: Mixing UI and Data Access Code in Visual Studio .NET
Picture 1: Mixing UI and Data Access Code in Visual Studio .NETOf course most people will immediately note some drawbacks in this approach. For example, it is not a good idea to have SQL code and database connection strings cluttered all over WinForms or ASP.NET pages. "OK", the .NET instructor will reply at this point, "then don't drop it on a form, drop it on a .NET component class. Make the connection string a dynamic property and bind it to a value in a .config file."
Fair enough. And as a side note I should mention that Visual Studio 2005 has somewhat improved here as well. It won't produce SQL code inside Windows forms any more. Visual Studio 2005 manages project-wide datasources, and places SQL code in so called TableAdapters, which are coupled with the underlying typed DataSet (actually the TableAdapter's code resides in a partial DataSet class file). Whether this is a good idea or not remains questionable.
What has not changed in Visual Studio 2005 is how the SQL query builder works. Once again it looks like a nice feature at first sight, at least if all you want is some straight-forward DataSet-to-Table mapping. In general, query builder is used for editing SQL code embedded in .NET Components. Based on database schema information, it can also auto-generate select-, insert-, update- and delete-statements. Here we can see query builder in action:
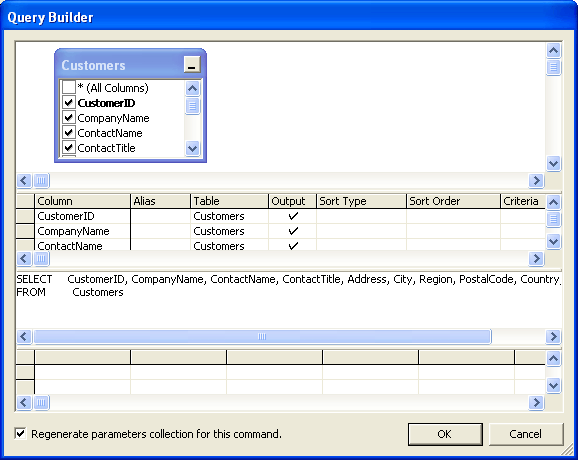 Picture 2: Visual Studio .NET Query Builder
Picture 2: Visual Studio .NET Query BuilderWhen a DataAdapter has been placed onto a Component's tray, query builder is the only way how to edit the SQL code attached to the DataAdapter's commands, as the SQL code format was certainly not designed for human readability:
 Picture 3: Resulting SQL Code
Picture 3: Resulting SQL CodeIt turns out that query builder might not be everybody's tool of choice (maybe with the exception of people with a background in Microsoft Access). Every additional (or removed) database attribute implies code re-generation or manual adaptation. There is no syntax highlighting, no testing capability, and to make things worse, query builder even tries to optimize logical expressions. There are scenarios when query builder definitely changes statement semantics.
ADO.NET is also missing support for database independence. Unlike JDBC and ODBC, which offer completely consistent APIs across all database systems and either are bound to a certain SQL standard or include some semantic extensions in order to address different SQL flavors, ADO.NET providers work in a very vendor-specific manner. While it is true that there exist interface definitions which each provider has to implement (e.g. System.Data.IDbConnection), those interfaces just represent a subset of overall functionality. It should be noted that ADO.NET provider model has improved with .NET 2.0 though.
Arguably there is always the alternative of hand-coding whatever data access feature or convenience function might be missing. But this implies that many people will end up implementing the same things over and over again (e.g. providing a storage system for SQL code, creating parameter-collections, instantiating DataAdapters, commands and connections, opening and closing connections, handling exceptions, managing transactions, encapsulating database-specifics, etc). While there are third party libraries available covering some of these areas many of those products either enforce a completely different programming model and/or involve a steep learning curve. So this is where the Vanilla Data Access Layer for .NET comes in.
Vanilla DAL is a framework for accessing relational databases with ADO.NET. It avoids the problems that RAD-style programming tends to impose, and at the same time helps improving developer productivity.
Features include:
- SQL statement externalization in XML-files
- Wrapping database-specific code, hence laying the groundwork for database independence
- SQL code generation based on DB or Dataset schema information
- Automatic transaction handling (no need to repeat the same begin transaction-try-commit-catch-rollback sequence over and over again) and transaction propagation on data access
- Optimistic locking without any handwritten code
- SQL statement tracing
- Several convenience functions of common interest
Part 2 of the Vanilla DAL article series can be found here.
Thursday, December 07, 2006
When Web Design Goes Wrong
Great article that pretty much sums up the various ways of how web design can go wrong. Also includes some funny videos of website visitors losing their nerve.


Friday, December 01, 2006
Hibernate Reverse Engineering And SqlServer Identity Columns
I might be wrong on this, but it seems to me that the latest Hibernate Tools produce wrong mapping configuration for SqlServer identity (aka auto-increment) columns. While I'd expect
what I get is
which leads to a database error at runtime as Hibernate tries to create the primary key value, unless I change the setting back to "identity". I use Microsoft's latest JDBC driver. No big deal though, because Hibernate allows to define the reverse engineering strategy in great detail, so this behavior can easily be overridden. It's also quite likely I am doing something wrong to begin with, because I haven't found any existing bug report on this issue.
More Hibernate postings:
<generator class="identity" />what I get is
<generator class="assigned" />which leads to a database error at runtime as Hibernate tries to create the primary key value, unless I change the setting back to "identity". I use Microsoft's latest JDBC driver. No big deal though, because Hibernate allows to define the reverse engineering strategy in great detail, so this behavior can easily be overridden. It's also quite likely I am doing something wrong to begin with, because I haven't found any existing bug report on this issue.
More Hibernate postings:
Wednesday, November 29, 2006
.NET XML Serialization: SoapFormatter Vs. XmlSerializer
Depending on what you are trying to accomplish with XML serialization, there are two different approaches currently supported by the .NET framework. While XmlSerializer focuses on mapping .NET classes to XSD datatypes and provides a lot of flexibility for customizing the serialization format (by applying System.Xml.Serialization.Xml*Attribute annotations), SoapFormatter has it's strength in general purpose serialization and deserialization. SoapFormatter embeds type information as part of the serialization format, which ensures type safety but limits interoperability. And that's why - albeit the name - XmlSerializer is applied within .NET's Webservice stack, and not SoapFormatter. SoapFormatter and BinaryFormatter are used for .NET Remoting.
Additional information on this topic is available from this TopXML article.
Additional information on this topic is available from this TopXML article.
Wednesday, November 22, 2006
Vanilla DAL 0.2.3 Released
I just published Vanilla DAL 0.2.3 at Sourceforge. This release mainly consists of bugfixes.
From the project description:
Vanilla DAL is a data access framework for RDBMS on top of ADO.NET. It provides DB independence, SQL externalization via XML, automatic transaction management, on-the-fly SQL generation for datasets and convenience implementations for ever recurring tasks.
From the project description:
Vanilla DAL is a data access framework for RDBMS on top of ADO.NET. It provides DB independence, SQL externalization via XML, automatic transaction management, on-the-fly SQL generation for datasets and convenience implementations for ever recurring tasks.
Saturday, November 18, 2006
Wednesday, November 15, 2006
Meeting Ron Jacobs
Ron Jacobs did a talk on SOA patterns and antipatterns at the Upperaustrian .NET Usergroup last Monday. Ron is a long-term Microsoft employee and currently holds the position of Architect Evangelist. He is also famous for the MSDN Channel 9 ARCast podcast, which he is hosting. I have been listening to ARCast more or less since the beginning, and would strongly recommend it to everybody who is working with Microsoft technologies and enjoys listening to tech podcasts.
I also had the chance to chat with Ron after his presentation. It was really nice to meet him "in real life".
I also had the chance to chat with Ron after his presentation. It was really nice to meet him "in real life".
Tuesday, November 14, 2006
W-JAX Summary
W-JAX 2006 was a nice, well-organized conference. Unfortunately I was not so lucky with all the tracks I chose to listen to - I went to some presentations which were less tech-savvy, some on management perspectives, some about analysis issues, and noticed once more how little I care about that. On day two and three I went back to the tech talks and life was good again.
 Part of the W-JAX crowd. Third table row, right next to the aisle, grey sweater, that's me.
Part of the W-JAX crowd. Third table row, right next to the aisle, grey sweater, that's me.
On my way home I met Juergen Hoeller at the train. Juergen is a lead developer on the Spring framework project. Both of us used to study CompSci at University of Linz in the mid-90s. So this gave me the opportunity to pepper him with questions about Spring 2.0 and on where J2EE is heading in his opinion. He was patient enough to answer all of them. Thanks Juergen!
 Part of the W-JAX crowd. Third table row, right next to the aisle, grey sweater, that's me.
Part of the W-JAX crowd. Third table row, right next to the aisle, grey sweater, that's me.On my way home I met Juergen Hoeller at the train. Juergen is a lead developer on the Spring framework project. Both of us used to study CompSci at University of Linz in the mid-90s. So this gave me the opportunity to pepper him with questions about Spring 2.0 and on where J2EE is heading in his opinion. He was patient enough to answer all of them. Thanks Juergen!
Sunday, November 12, 2006
Stalking James Gosling
Hilarious video, though I do hope this is a body double in the final scene... ;-)
Saturday, November 04, 2006

Thursday, November 02, 2006
Why J2EE Projects Succeed Or Fail
Excellent compilation of main factors for success or failure of J2EE projects by "Raj Kul" at TheServerSide.Com. I whole heartedly agree.
1. Gap between Business Analysts and Technical Architects:
Business Analysts need to translate the business requirements in simple language which can be clearly understood by the Technical Architects. On the other hand, the Technical Architects need to have some understanding on the business domain. Both of them can come up with simple glossary documents covering 'Business Terminology' and 'Technical Terminology' which will help them to understand what the other person is talking.
2. Missing Non Functional Requirements:
J2EE may not help in achieving NFRs in the end. Yes, few parameters can be tuned to achieve few of the NFR goals. Critical NFRs must be clearly understood in the initial stages and should be considered in the Architecture / Design / implementation / QA-Testing stages. Project is considered as failure when the NFRs are missed by huge margins.
3. Architects role:
Technical Architect plays a major role in overall application success. Architect needs to put the application building blocks in place by considering NFRs, possible appropriate J2EE technologies, etc. Architect should evaluate multiple possible options before settling on any one approach including partitioning of application / technology choice (J2EE != EJB) / communication protocols, etc. Architect should deliver detailed architecture and design documents well in advance which can be reviewed and discussed with senior members of team
4. Understanding of J2EE technologies:
Not everybody from the development team is J2EE expert. Few of the members may be new to J2EE and needs to gear / brush up J2EE skills. Simple crash course on the project specific technologies and J2EE best practices will definitely help before the actual development starts.
5. Ongoing code review:
The ongoing code reviews will help to verify that standard J2EE best practices are in place, design patterns are implemented correctly, coding standards are followed throughout the application, etc.
6. Use of productivity tools:
Project teams should incorporate productivity tools in their development environment. These tools can include XDoclet, Checkstyle, PMD, Jalopy, etc. The team should have standard development IDE and build system in place.
7. Continuous testing and QA:
Iterative and incremental development will achieve continuous testing and QA of deliverables. Standard bug tracking system should be in place and quality champions should track the overall progress with respect to quality. Application developer should spend time on unit testing. JUnit kind of unit testing frameworks should be made mandatory in project.
8. Adherence to J2EE specifications:
Project teams need to stick to J2EE specifications and not to the underlying container specific APIs. These APIs are good in short term but in long term they will act as trap and you will loose WORA facility guaranteed by Java / J2EE.
9. Simple but working approach:
Client needs working solution not the big technology stack. Over-designing the applications will not only take more time but will increase the chances of failure. Client requirements can be broken down in small sub systems and releases should be planned in such a way that client will get started on the application early. Even in small blocks when client see the working system, his and development team's confidence will go up and obviously the chances of success will go high.
10. Use of Open Source components:
Do not build everything on your own. There are several J2EE related open source technologies available on web. Use them (after evaluation and testing obviously) wherever possible. You can also modify them if needed for your application needs. This will help in saving development time. For example, displaytag utility can be used as navigational component.
1. Gap between Business Analysts and Technical Architects:
Business Analysts need to translate the business requirements in simple language which can be clearly understood by the Technical Architects. On the other hand, the Technical Architects need to have some understanding on the business domain. Both of them can come up with simple glossary documents covering 'Business Terminology' and 'Technical Terminology' which will help them to understand what the other person is talking.
2. Missing Non Functional Requirements:
J2EE may not help in achieving NFRs in the end. Yes, few parameters can be tuned to achieve few of the NFR goals. Critical NFRs must be clearly understood in the initial stages and should be considered in the Architecture / Design / implementation / QA-Testing stages. Project is considered as failure when the NFRs are missed by huge margins.
3. Architects role:
Technical Architect plays a major role in overall application success. Architect needs to put the application building blocks in place by considering NFRs, possible appropriate J2EE technologies, etc. Architect should evaluate multiple possible options before settling on any one approach including partitioning of application / technology choice (J2EE != EJB) / communication protocols, etc. Architect should deliver detailed architecture and design documents well in advance which can be reviewed and discussed with senior members of team
4. Understanding of J2EE technologies:
Not everybody from the development team is J2EE expert. Few of the members may be new to J2EE and needs to gear / brush up J2EE skills. Simple crash course on the project specific technologies and J2EE best practices will definitely help before the actual development starts.
5. Ongoing code review:
The ongoing code reviews will help to verify that standard J2EE best practices are in place, design patterns are implemented correctly, coding standards are followed throughout the application, etc.
6. Use of productivity tools:
Project teams should incorporate productivity tools in their development environment. These tools can include XDoclet, Checkstyle, PMD, Jalopy, etc. The team should have standard development IDE and build system in place.
7. Continuous testing and QA:
Iterative and incremental development will achieve continuous testing and QA of deliverables. Standard bug tracking system should be in place and quality champions should track the overall progress with respect to quality. Application developer should spend time on unit testing. JUnit kind of unit testing frameworks should be made mandatory in project.
8. Adherence to J2EE specifications:
Project teams need to stick to J2EE specifications and not to the underlying container specific APIs. These APIs are good in short term but in long term they will act as trap and you will loose WORA facility guaranteed by Java / J2EE.
9. Simple but working approach:
Client needs working solution not the big technology stack. Over-designing the applications will not only take more time but will increase the chances of failure. Client requirements can be broken down in small sub systems and releases should be planned in such a way that client will get started on the application early. Even in small blocks when client see the working system, his and development team's confidence will go up and obviously the chances of success will go high.
10. Use of Open Source components:
Do not build everything on your own. There are several J2EE related open source technologies available on web. Use them (after evaluation and testing obviously) wherever possible. You can also modify them if needed for your application needs. This will help in saving development time. For example, displaytag utility can be used as navigational component.
Saturday, October 28, 2006
Where In The World Is Poland?
Did you ever take a closer look at the timezone tab on the Windows date and time panel? Depending on your Windows version, it is quite likely that Poland seems to be flooded on the timezone world map. Raymond Chen knows why.


Just Another Sudoku Solver (C++)
Closing this topic, here is the sourcecode of the C++ Sudoku Solver (originally in Java). Remember that this a template class, so all this code has to go to a header file. All allocation actions should be the same as under Java - which is important for runtime behavior comparison.
I coded this last night between 1am and 2am in the morning, so please don't shoot me in case of any mistakes ;-).
Previos Posts:
Follow-Ups:
I coded this last night between 1am and 2am in the morning, so please don't shoot me in case of any mistakes ;-).
#pragma once
#include <vector>
#include <math.h>
template<int D> class Sudoku
{
public:
Sudoku(int _startGrid[D][D])
{
solutions = new std::vector<int(*)[D]>();
dimSqrt = (int)sqrt((double)D);
for (int x = 0; x < D; x++) {
for (int y = 0; y < D; y++) {
squareIdx[x][y] =
(x / dimSqrt) * dimSqrt + (y / dimSqrt);
}
}
copyGrid(_startGrid, startGrid);
}
virtual ~Sudoku() {
for (std::vector<int(*)[D]>::iterator it =
solutions->begin(); it != solutions->end(); it++) {
delete[] *it;
}
delete solutions;
}
std::vector<int(*)[D]>* solve() {
for (std::vector<int(*)[D]>::iterator it =
solutions->begin(); it != solutions->end(); it++) {
delete[] *it;
}
solutions->clear();
copyGrid(startGrid, grid);
for (int i = 0; i < D; i++) {
for (int j = 0; j < D; j++) {
usedInRow[i][j] = false;
usedInColumn[i][j] = false;
usedInSquare[i][j] = false;
}
}
for (int x = 0; x < D; x++) {
for (int y = 0; y < D; y++) {
int val = grid[x][y];
if (val != 0) {
usedInRow[x][val - 1] = true;
usedInColumn[y][val - 1] = true;
usedInSquare[squareIdx[x][y]][val - 1] = true;
}
}
}
digInto(0, 0);
return solutions;
}
private:
void copyGrid(int src[D][D], int tgt[D][D]) {
for (int x = 0; x < D; x++) {
// for compatibility reasons with java we
// copy one-dimensional arrays only
memcpy(tgt[x], src[x], D * sizeof(int));
}
};
void digInto(int x, int y) {
if (startGrid[x][y] == 0) {
int square = squareIdx[x][y];
for (int val = 1; val <= D; val++) {
int valIdx = val - 1;
if (usedInRow[x][valIdx] || usedInColumn[y][valIdx] ||
usedInSquare[square][valIdx]) {
continue;
}
grid[x][y] = val;
usedInRow[x][valIdx] = true;
usedInColumn[y][valIdx] = true;
usedInSquare[square][valIdx] = true;
if (x < D - 1) {
digInto(x + 1, y);
}
else if (y < D - 1) {
digInto(0, y + 1);
}
else {
addSolution();
}
grid[x][y] = 0;
usedInRow[x][valIdx] = false;
usedInColumn[y][valIdx] = false;
usedInSquare[square][valIdx] = false;
}
}
else {
if (x < D - 1) {
digInto(x + 1, y);
}
else if (y < D - 1) {
digInto(0, y + 1);
}
else {
addSolution();
}
}
};
void addSolution() {
int (*solution)[D] = new int[D][D];
copyGrid(grid, solution);
solutions->push_back(solution);
};
int startGrid[D][D];
int grid[D][D];
int dimSqrt;
std::vector<int(*)[D]>* solutions;
bool usedInColumn[D][D];
bool usedInRow[D][D];
bool usedInSquare[D][D];
int squareIdx[D][D];
};
Previos Posts:
Follow-Ups:
Friday, October 27, 2006
Computers In Old Movies
A colleague of mine - knowing about my interest for ancient computers - recently asked me whether I knew which system they were using in the 1968 movie "Hot Millions" with Peter Ustinov. I remember having seen this picture once, and I also remember they had a mainframe in the scenery. But the only image I could look up in internet is this one with Ustinov sitting in front of a terminal. I guess I will have to watch "Hot Millions" again in order to find out.

Anyway, this question caught my attention, so I did some more research and discovered that the first appearance of a computer in a cinema movie was probably a mockup named "EMERAC" (reminiscenting about ENIAC or UNIVAC?) in "Desk Set" with Katherine Hepburn from 1957. It even consisted of real computer parts, namely IBM 704 magnetic tapes and some panels from the famous SAGE military computer (based on vacuum tubes and ferrite core memory).

No list of computers in old movies would not be complete without HAL9000 from "A Space Odyssey". Timeless.

Anyway, this question caught my attention, so I did some more research and discovered that the first appearance of a computer in a cinema movie was probably a mockup named "EMERAC" (reminiscenting about ENIAC or UNIVAC?) in "Desk Set" with Katherine Hepburn from 1957. It even consisted of real computer parts, namely IBM 704 magnetic tapes and some panels from the famous SAGE military computer (based on vacuum tubes and ferrite core memory).

No list of computers in old movies would not be complete without HAL9000 from "A Space Odyssey". Timeless.

Java Vs. .NET Vs. C++ Performance
Well I am done with porting my little Sudoku Solver to C++. I took care to keep the algorithm equivalent, esp. on memory allocation (actually the only memory that is dynamically allocated is for storing away puzzle solutions). Not really surprisingly, C++ beats both C# and Java:
I calculated the execution time by feeding the solver with a sparsely populated puzzle that has thousands of valid solutions (Sudoku purists will point out that this is a non-well-formed puzzle). The algorithm uses a slightly optimized brute force approach (my intention was runtime comparison, not building a hyperfast solver algorithm) - so it finds all the solutions.
The algorithm, when implemented in C++, delivers around 60.000 valid solutions per second on my 2.4GHz Athlon for average one-solution 9x9 Sudoku puzzles. The time it takes to solve one of those can hardly be measured, and I didn't want to inject the same puzzle a thousand times for the benchmark.
It depends heavily on the intial puzzle values, though. I digged out a puzzle - one that is considered more or less unbreakable for humans - that took the C++ implementation 15ms to solve. 15ms for one solution, mind you.
I doubt that there is a lot of optimzing potential for Java Hotspot other but compiling the algorithm's main method (which only consists of a few lines of code anyway) to native code as soon as possible. Dynamic memory allocation only happens for storing away solution arrays, and those are not going to be garbage collected until the end, so there is not a lot of optimizing potential on the memory management side. The .NET CLR should JIT all of the code at startup anyway. I did some tests to go sure, and the numbers did not change neither under Java and nor under .NET even after running the same stack of puzzles many times in a row.
Previos Posts:
Follow-Ups:
| Platform | Execution Time (for several thousand valid solutions) |
| C++ | 250ms |
| C# (.NET 1.1) after NGEN | 390ms |
| Java (JDK 1.4.2) | 680ms |
| C# (.NET 1.1) | 790ms |
I calculated the execution time by feeding the solver with a sparsely populated puzzle that has thousands of valid solutions (Sudoku purists will point out that this is a non-well-formed puzzle). The algorithm uses a slightly optimized brute force approach (my intention was runtime comparison, not building a hyperfast solver algorithm) - so it finds all the solutions.
The algorithm, when implemented in C++, delivers around 60.000 valid solutions per second on my 2.4GHz Athlon for average one-solution 9x9 Sudoku puzzles. The time it takes to solve one of those can hardly be measured, and I didn't want to inject the same puzzle a thousand times for the benchmark.
It depends heavily on the intial puzzle values, though. I digged out a puzzle - one that is considered more or less unbreakable for humans - that took the C++ implementation 15ms to solve. 15ms for one solution, mind you.
I doubt that there is a lot of optimzing potential for Java Hotspot other but compiling the algorithm's main method (which only consists of a few lines of code anyway) to native code as soon as possible. Dynamic memory allocation only happens for storing away solution arrays, and those are not going to be garbage collected until the end, so there is not a lot of optimizing potential on the memory management side. The .NET CLR should JIT all of the code at startup anyway. I did some tests to go sure, and the numbers did not change neither under Java and nor under .NET even after running the same stack of puzzles many times in a row.
Previos Posts:
Follow-Ups:
Thursday, October 26, 2006
Java Vs. .NET Performance
As a sidenote, I just ported yesterday's Sudoku Solver to C#, ran the same stack of puzzles, and compared execution times. Here is the result:
What I did here was to feed the solver with a sparsely populated puzzle that has thousands of valid solutions, and measure the time of execution to find all the solutions in a brute-force manner. Just finding one solution would be beyond the scale of time measurement.
Right now I am working on a C++ port, so this will be another interesting comparison (my C++ coding is slower than it used to be, since I have not written a single line of C++ over the last two years).
| Platform | Execution Time (for several thousand valid solutions) |
| Java (JDK 1.4.2) | 680ms |
| C# (.NET 1.1) | 790ms |
| C# (.NET 1.1) after NGEN | 390ms |
What I did here was to feed the solver with a sparsely populated puzzle that has thousands of valid solutions, and measure the time of execution to find all the solutions in a brute-force manner. Just finding one solution would be beyond the scale of time measurement.
Right now I am working on a C++ port, so this will be another interesting comparison (my C++ coding is slower than it used to be, since I have not written a single line of C++ over the last two years).
Vanilla DAL 0.2.2 Released
I received some valuable feedback from some projects employing the Vanilla .NET Data Access Framework, so the following changes have been incorporated in release 0.2.2:
- SqlServer: quoted identifiers for table names and column names (square brackets).
- New Property FillParameter.SchemaHandling for defining whether DataSet schema should be preserved or updated by DB schema.
- SQL code may now be passed in directly, as well as pre-processed before execution. The sample application provides more details.
- Class "StatementID" has been renamed to "Statement".
Wednesday, October 25, 2006
Just Another Sudoku Solver
Yes, it's only brute force (just avoiding digging deeper into the search tree when it's proven wrong already), and yes, it's Java which implies array bounds checking, but it still delivers around 30.000 valid solutions per second for average 9x9 Sudokus on my 2.4GHz Athlon. Faster than my father-in-law who has been messing around with a single puzzle all night long. I couldn't watch it any longer [;-)], so I hacked in the following code.
Follow-Ups:
package com.arnosoftwaredev.sudoku;
import java.util.ArrayList;
import java.util.Collection;
public class Sudoku {
private int[][] startGrid;
private int dim;
private int dimSqrt;
private ArrayList solutions;
private boolean usedInColumn[][];
private boolean usedInRow[][];
private boolean usedInSquare[][];
private int squareIdx[][];
private int grid[][];
public Sudoku(int[][] startGridParam) {
if (startGridParam == null) {
throw new IllegalArgumentException("Grid is invalid");
}
if (startGridParam.length == 0) {
throw new IllegalArgumentException("Grid is invalid");
}
if (startGridParam.length != startGridParam[0].length) {
throw new IllegalArgumentException("Grid is invalid");
}
dim = startGridParam.length;
if (dim != 4 && dim != 9 && dim != 16 && dim != 25) {
throw new IllegalArgumentException("Grid is invalid");
}
solutions = new ArrayList();
dimSqrt = (int) Math.round(Math.sqrt(dim));
usedInColumn = new boolean[dim][dim];
usedInRow = new boolean[dim][dim];
usedInSquare = new boolean[dim][dim];
squareIdx = new int[dim][dim];
startGrid = new int[dim][dim];
grid = new int[dim][dim];
for (int x = 0; x < dim; x++) {
for (int y = 0; y < dim; y++) {
squareIdx[x][y] =
(x / dimSqrt) * dimSqrt + (y / dimSqrt);
}
}
copyGrid(startGridParam, startGrid);
}
private void copyGrid(int[][] src, int[][] tgt) {
for (int x = 0; x < src.length; x++) {
System.arraycopy(src[x], 0, tgt[x], 0, src[x].length);
}
}
private void digInto(int x, int y) {
if (startGrid[x][y] == 0) {
int square = squareIdx[x][y];
for (int val = 1; val <= dim; val++) {
int valIdx = val - 1;
if (usedInRow[x][valIdx] || usedInColumn[y][valIdx] ||
usedInSquare[square][valIdx]) {
continue;
}
grid[x][y] = val;
usedInRow[x][valIdx] = true;
usedInColumn[y][valIdx] = true;
usedInSquare[square][valIdx] = true;
if (x < dim - 1) {
digInto(x + 1, y);
}
else if (y < dim - 1) {
digInto(0, y + 1);
}
else {
addSolution();
}
grid[x][y] = 0;
usedInRow[x][valIdx] = false;
usedInColumn[y][valIdx] = false;
usedInSquare[square][valIdx] = false;
}
}
else {
if (x < dim - 1) {
digInto(x + 1, y);
}
else if (y < dim - 1) {
digInto(0, y + 1);
}
else {
addSolution();
}
}
}
private void addSolution() {
int[][] solution = new int[dim][dim];
copyGrid(grid, solution);
solutions.add(solution);
}
public Collection solve() {
solutions.clear();
copyGrid(startGrid, grid);
for (int i = 0; i < dim; i++) {
for (int j = 0; j < dim; j++) {
usedInRow[i][j] = false;
usedInColumn[i][j] = false;
usedInSquare[i][j] = false;
}
}
for (int x = 0; x < dim; x++) {
for (int y = 0; y < dim; y++) {
int val = grid[x][y];
if (val != 0) {
usedInRow[x][val - 1] = true;
usedInColumn[y][val - 1] = true;
usedInSquare[squareIdx[x][y]][val - 1] = true;
}
}
}
digInto(0, 0);
return solutions;
}
}Follow-Ups:
Tuesday, October 24, 2006
The Software Projekt Triangle
From Microsoft Project Online:
If time, money, or what your project accomplished were unlimited, you wouldn't need to do project management. Unfortunately, most projects have a specific time limit, budget and scope.
It is this combination of elements (schedule, money and scope) that we refer to as the project triangle. Understanding the project triangle will allow you to make better choices when you need to make tradeoffs. If you adjust any one side of the triangle, the other two sides are affected.
For example, if you decide to adjust the project plan to
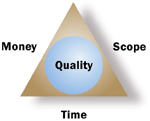
Quality is at the center of the project triangle. Quality affects every side of the triangle, and any changes you make to any side of the triangle are likely to affect quality. Quality is not a factor of the triangle; it is a result of what you do with time, money, and scope.
For example, if you find you have additional time in your schedule, you might be able to increase scope by adding tasks and duration. With this extra time and scope, you can build a higher level of quality into the project and its deliverables.
Or if you need to cut costs to meet your budget, you might have to decrease scope by cutting tasks or reducing task durations. With decreased scope, there might be fewer opportunities to achieve a certain level of quality, so a lower quality results from the need to cut costs.
Jeff Atwood even carpented "the iron stool of software project management" out of this.
If time, money, or what your project accomplished were unlimited, you wouldn't need to do project management. Unfortunately, most projects have a specific time limit, budget and scope.
It is this combination of elements (schedule, money and scope) that we refer to as the project triangle. Understanding the project triangle will allow you to make better choices when you need to make tradeoffs. If you adjust any one side of the triangle, the other two sides are affected.
For example, if you decide to adjust the project plan to
- Bring in the scheduled finish date, you might end up with increased costs and a decreased scope.
- Meet the project budget, the result might be a longer schedule and a decreased scope.
- Increase scope, your project might take more time and cost more money in the form of resources

Quality is at the center of the project triangle. Quality affects every side of the triangle, and any changes you make to any side of the triangle are likely to affect quality. Quality is not a factor of the triangle; it is a result of what you do with time, money, and scope.
For example, if you find you have additional time in your schedule, you might be able to increase scope by adding tasks and duration. With this extra time and scope, you can build a higher level of quality into the project and its deliverables.
Or if you need to cut costs to meet your budget, you might have to decrease scope by cutting tasks or reducing task durations. With decreased scope, there might be fewer opportunities to achieve a certain level of quality, so a lower quality results from the need to cut costs.
Jeff Atwood even carpented "the iron stool of software project management" out of this.
Wednesday, October 18, 2006
Macs Do Windows Too
Harsh words on the Apple Boot Camp site (Boot Camp lets you install Windows XP on Intel-based Macs), e.g.:
Good for Apple that they don't have to worry about backward compatibility on old hardware. I also remember the pre-2002 era, when Mac OS still lacked memory protection and preemptive multitasking. How "1980s" does that sound?
Macs use an ultra-modern industry standard technology called EFI to handle booting. Sadly, Windows XP, and even the upcoming Vista, are stuck in the 1980s with old-fashioned BIOS. But with Boot Camp, the Mac can operate smoothly in both centuries.
Good for Apple that they don't have to worry about backward compatibility on old hardware. I also remember the pre-2002 era, when Mac OS still lacked memory protection and preemptive multitasking. How "1980s" does that sound?
Wednesday, October 11, 2006
Saturday, September 16, 2006
.NET 2.0, HttpWebRequest.KeepAlive And ServicePoint.ConnectionLimit
Since switching over to .NET 2.0, one of our applications occasionally threw "The request was aborted: The request was canceled." resp. "The underlying connection was closed: The request was canceled." errors. This happened maybe 1 out of 25 times when connecting to another server using HTTP, either directly via HttpWebRequest or on webservice calls, which also apply HttpWebRequest internally.
Digging further into the issue, it turned out that several people suggested to set HttpWebRequest.KeepAlive to false. And as matter of fact this worked. But KeepAlive=false will most likely imply a performance penalty as there won't be any re-use (also known as HTTP pipelining) of TCP-connections. TCP-connections are now closed immediately and reopened on each HTTP-request. To make things worse, we have SSL turned on, with both server and client certificates, so KeepAlive=false will then cause a complete SSL-Handshake now for each and every HTTP request to the same server. As a sidenote, KeepAlive=true with client authentication requires the initial authentication to be shared between all following requests, hence it is necessary to set HttpWebRequest.UnsafeAuthenticatedConnectionSharing=true. Please consult the MSDN documentation for more information about what that implies.
Back to the original topic, our application used to work fine under .NET 1.1, only .NET 2.0 seems to have this problem. And despite the fact that people have posted this issue over and over again, there is no Microsoft hotfix up to this day. KeepAlive=false is the only remedy.
By the way, another property that is essential for network throughput under .NET is HttpWebRequest.ServicePoint.ConnectionLimit. Microsoft started limiting the maximum number of parallel network connections some time ago (I once read in order to prevent malware from flooding the network - which sounds unlikely given that one can simply raise this limit programmatically, at least with admin credentials), and while this might not harm the single user when surfing the web, it surely is not suited for other kinds of applications. After the limit is reached, further request will be queued and have to wait for a running request to terminate. I am sure there are quite some applications out there which run into performance problems because of this.
The preset connection limit might vary depending on the underlying operating system and hosting environment. It can be changed programmatically by setting HttpWebRequest.ServicePoint.ConnectionLimit to a higher value, or in one of .NET's .config files (machine.config, app.config resp. web.config):
This is just one of many possible explanations, but that unfortunate limitation might boil down to a particular interpretation of RFC 2616 (HTTP1.1), which states:
So is any .NET application considered "single-user client" by default? Our system surely isn't a single-user client, it's more like a kind of proxy, with plenty of concurrent users and HTTP connections. And how many developers might now even have heard about this setting, and will find out once their application went into production?
Also note that phrase of "persistent connections". Of course it is a bad idea for the client to hold hundreds of connections captive and thus bringing the server to its knee. But as I have mentioned, we cannot pool any connections anyway, not even a few of them, thank's to .NET 2.0's "The request was aborted: The request was canceled."-bug.
Anyway, it's the server's responsiblitlity to determine when too many connections are kept alive. After all, HTTP-KeepAlive is something that the client might ask for, but that the server may always decline.
Digging further into the issue, it turned out that several people suggested to set HttpWebRequest.KeepAlive to false. And as matter of fact this worked. But KeepAlive=false will most likely imply a performance penalty as there won't be any re-use (also known as HTTP pipelining) of TCP-connections. TCP-connections are now closed immediately and reopened on each HTTP-request. To make things worse, we have SSL turned on, with both server and client certificates, so KeepAlive=false will then cause a complete SSL-Handshake now for each and every HTTP request to the same server. As a sidenote, KeepAlive=true with client authentication requires the initial authentication to be shared between all following requests, hence it is necessary to set HttpWebRequest.UnsafeAuthenticatedConnectionSharing=true. Please consult the MSDN documentation for more information about what that implies.
Back to the original topic, our application used to work fine under .NET 1.1, only .NET 2.0 seems to have this problem. And despite the fact that people have posted this issue over and over again, there is no Microsoft hotfix up to this day. KeepAlive=false is the only remedy.
By the way, another property that is essential for network throughput under .NET is HttpWebRequest.ServicePoint.ConnectionLimit. Microsoft started limiting the maximum number of parallel network connections some time ago (I once read in order to prevent malware from flooding the network - which sounds unlikely given that one can simply raise this limit programmatically, at least with admin credentials), and while this might not harm the single user when surfing the web, it surely is not suited for other kinds of applications. After the limit is reached, further request will be queued and have to wait for a running request to terminate. I am sure there are quite some applications out there which run into performance problems because of this.
The preset connection limit might vary depending on the underlying operating system and hosting environment. It can be changed programmatically by setting HttpWebRequest.ServicePoint.ConnectionLimit to a higher value, or in one of .NET's .config files (machine.config, app.config resp. web.config):
<system.net>
<connectionManagement>
<add address="yourtargetdomain.com" maxconnection="32">
</add>
</connectionManagement>
</system.net>
This is just one of many possible explanations, but that unfortunate limitation might boil down to a particular interpretation of RFC 2616 (HTTP1.1), which states:
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. A proxy SHOULD use up to 2*N connections to another server or proxy, where N is the number of simultaneously active users. These guidelines are intended to improve HTTP response times and avoid congestion.
So is any .NET application considered "single-user client" by default? Our system surely isn't a single-user client, it's more like a kind of proxy, with plenty of concurrent users and HTTP connections. And how many developers might now even have heard about this setting, and will find out once their application went into production?
Also note that phrase of "persistent connections". Of course it is a bad idea for the client to hold hundreds of connections captive and thus bringing the server to its knee. But as I have mentioned, we cannot pool any connections anyway, not even a few of them, thank's to .NET 2.0's "The request was aborted: The request was canceled."-bug.
Anyway, it's the server's responsiblitlity to determine when too many connections are kept alive. After all, HTTP-KeepAlive is something that the client might ask for, but that the server may always decline.
Wednesday, September 13, 2006
Jeff Atwood Takes On Joel Spolsky
Jeff Atwood openly asks if Joel Spolsky "jumped the shark" because of implementing their his company's flagship product FogBugz in an in-house Basic-dialect called "Wasabi". Wasabi can then be compiled to VBScript or PHP, depending on customers' requirements.
Back when I read about this approach, it made me raise an eyebrow as well. I remember thinking, "boy I thought I'd like to work at Fog Creek, but having to code in such a proprietary language would be no-go". And I was wondering if that wouldn't contradict their frequently mentioned efforts of trying to attract great programmers. Actually, of the best programmers I know, nobody would ever voluntarily program in something like VB or VBScript, let go Wasabi.
But he then went on describing how this decision made sense from a business point (platform independence at a minimum of effort, no complete rewrite necessary), so I said OK, I might not like it from a developer's perspective, but from a business perspective it could make sense.
Now Jeff Atwood probably is a more censorious person than me. He decided to rip apart Joel's argumentation and connect the Wasabi-story with Joel's criticism of Ruby. He continued to make some pretty hefty statements like "fifty thousand programmers' heads simultaneously exploding", "absolutely beyond the pale" or "amplifies the insanity". I usually like Jeff's artwork, but attaching a big red WTF label on Joel's forehead is not really subtle either. And the flaming continued in the comment sections of both blogs.
My recommendation: Please settle down! From reading one or two paragraphs in some Joel on Software article, nobody possesses the same amount of information that Joel Spolsky was basing his decision on. Also, recognizing that what seems right from a developer's view must not always be right from a business standpoint is something that many programmers still have to get into their minds.
But hey, let's not hang on each of Joel Spolsky's words either. He certainly is an extraordinary programmer and writer, but he might be mistaken as well at times (a possibility he openly admits).
Back when I read about this approach, it made me raise an eyebrow as well. I remember thinking, "boy I thought I'd like to work at Fog Creek, but having to code in such a proprietary language would be no-go". And I was wondering if that wouldn't contradict their frequently mentioned efforts of trying to attract great programmers. Actually, of the best programmers I know, nobody would ever voluntarily program in something like VB or VBScript, let go Wasabi.
But he then went on describing how this decision made sense from a business point (platform independence at a minimum of effort, no complete rewrite necessary), so I said OK, I might not like it from a developer's perspective, but from a business perspective it could make sense.
Now Jeff Atwood probably is a more censorious person than me. He decided to rip apart Joel's argumentation and connect the Wasabi-story with Joel's criticism of Ruby. He continued to make some pretty hefty statements like "fifty thousand programmers' heads simultaneously exploding", "absolutely beyond the pale" or "amplifies the insanity". I usually like Jeff's artwork, but attaching a big red WTF label on Joel's forehead is not really subtle either. And the flaming continued in the comment sections of both blogs.
My recommendation: Please settle down! From reading one or two paragraphs in some Joel on Software article, nobody possesses the same amount of information that Joel Spolsky was basing his decision on. Also, recognizing that what seems right from a developer's view must not always be right from a business standpoint is something that many programmers still have to get into their minds.
But hey, let's not hang on each of Joel Spolsky's words either. He certainly is an extraordinary programmer and writer, but he might be mistaken as well at times (a possibility he openly admits).
Friday, September 01, 2006
Vanilla DAL Data Access Framework For SqlServer, Oracle and OleDB
Version 0.2.0 of the Vanilla DAL Data Access Framework adds support for OleDB and Oracle databases.
Thursday, August 31, 2006
Vanilla DAL: Added Support For OleDB And Oracle
3:00am in the morning, I finally managed to add support for Oracle and for the generic OleDb ADO.NET provider (using MS Access, as this was all I had available) to Vanilla DAL. Client code stays free of database specifics, but I am still wondering what to do with SQL statements. Vanilla DAL enforces SQL statement externalization in XML resp. generates SQL on-the-fly, but I can't (and won't) prevent the developer from applying vendor-dependent SQL syntax. The format of parameter placeholders is vendor-specific as well... I am probably going to set up one global standard, and wrap away vendor details for SQL parameters.
I am planning to publish Vanilla DAL 0.2.0 within the coming week. Next task will be to provide documentation and more samples. After that is done, it might have reached a state which allows me to start promoting this framework (it's more of a skunkworks project right now).
I am planning to publish Vanilla DAL 0.2.0 within the coming week. Next task will be to provide documentation and more samples. After that is done, it might have reached a state which allows me to start promoting this framework (it's more of a skunkworks project right now).
Wednesday, August 30, 2006
Vanilla DAL 0.1.2 Released
I just released version 0.1.2 of my .NET data access framework "Vanilla DAL". Currently I am working on support for Oracle and OleDB providers, and this release lays the groundwork for the oncoming changes on an API level. When this is done, Vanilla DAL will move from pre-alpha to alpha status.
Installing Oracle 10g express edition was a time-consuming task, as always with Oracle. Being a small footprint edition, it seems to be consuming too many system resources for my taste. On the other hand, the administration tools have improved tremendously (remember those Java rich clients on Oracle 8?). Anyway, my best Oracle days are long gone (Oracle 5 in 1992 on DOS, Oracle 7.3 and Oracle 8 between 1997 and 2001 on DEC VAX, Sun Solaris and finally Windows). This time I only plan to migrate my test database over there, get the Oracle-specific implementation done and that will be it.
I am not quite sure if I will manage to keep the complete API backward compatible to the previous releases, this mainly has to do with the fact that ADO.NET data providers enforce different SQL parameter naming conventions (e.g. @name under SqlServer, ? under OleDB, :name under Oracle). The most important issue is to prevent any DB-specific code in application modules. As there is no parameter name but only a parameter position under OleDB, I am still looking for the optimal mechanism to hide this detail from application code.
Installing Oracle 10g express edition was a time-consuming task, as always with Oracle. Being a small footprint edition, it seems to be consuming too many system resources for my taste. On the other hand, the administration tools have improved tremendously (remember those Java rich clients on Oracle 8?). Anyway, my best Oracle days are long gone (Oracle 5 in 1992 on DOS, Oracle 7.3 and Oracle 8 between 1997 and 2001 on DEC VAX, Sun Solaris and finally Windows). This time I only plan to migrate my test database over there, get the Oracle-specific implementation done and that will be it.
I am not quite sure if I will manage to keep the complete API backward compatible to the previous releases, this mainly has to do with the fact that ADO.NET data providers enforce different SQL parameter naming conventions (e.g. @name under SqlServer, ? under OleDB, :name under Oracle). The most important issue is to prevent any DB-specific code in application modules. As there is no parameter name but only a parameter position under OleDB, I am still looking for the optimal mechanism to hide this detail from application code.
Wednesday, August 23, 2006
Visual Studio .NET 2003 SP1
It's finally here.
Three and a half years after Visual Studio .NET 2003 had been published and nearly one year after it's successor Visual Studio .NET 2005 saw the dawn of light, the first service pack for 2003 became available last week. And it is going to save us tons of otherwise wasted time (we are still stuck with .NET 1.1 in this project because of some third-party libraries that just won't work under .NET 2.0).
Over the last years, we have experienced all kind of difficulties with Visual Studio 2003. One of my "favorites": Controls disappearing unpredictably in WinForms designer. After a while we even figured out what was going on under the hoods, how the designer generated initialization code in a different order when child controls were being added to parent controls, in case the parent controls had in turn had been created AFTER the child controls. This consecutively led the designer to throw away parts of the code during the next code generation cycle. We already knew how to rearrange the originally generated code segments, so we managed to prevent that from happening (if that does sound sick to you, you are not alone).
But one of the biggest productivity killers was the incredible amount of time it took WinForms designer to open complex forms, e.g. forms with lots of controls spread over several tabpages. It lasted minutes of up to 100% CPU usage on typical developer machines in 2003 (remember, no dualcores back then) and required close to a Gigabyte of additionally allocated memory. Sometimes the IDE crashed during the process and we had to start all over. I blamed the third-party controls we used. They probably misbehaved at design time. Never would Microsoft have left such a bug unpatched for more than three years, right?
Wrong!
The following CPU and memory usage charts represent the same activity - opening our most complex form in Visual Studio 2003 WinForms designer on a dualcore Pentium 4 3.0GHz with 2 Gigs of RAM.
Visual Studio 2003 w/o SP1: 90 seconds, memory allocation 800MB:
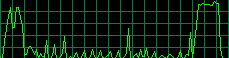 (Core 1)
(Core 1)
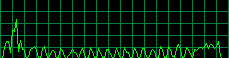 (Core 2)
(Core 2)
 (Memory)
(Memory)
Visual Studio 2003 SP1: 10 seconds, memory allocation 20MB:
 (Core 1)
(Core 1)
 (Core 2)
(Core 2)
 (Memory)
(Memory)
Three and a half years after Visual Studio .NET 2003 had been published and nearly one year after it's successor Visual Studio .NET 2005 saw the dawn of light, the first service pack for 2003 became available last week. And it is going to save us tons of otherwise wasted time (we are still stuck with .NET 1.1 in this project because of some third-party libraries that just won't work under .NET 2.0).
Over the last years, we have experienced all kind of difficulties with Visual Studio 2003. One of my "favorites": Controls disappearing unpredictably in WinForms designer. After a while we even figured out what was going on under the hoods, how the designer generated initialization code in a different order when child controls were being added to parent controls, in case the parent controls had in turn had been created AFTER the child controls. This consecutively led the designer to throw away parts of the code during the next code generation cycle. We already knew how to rearrange the originally generated code segments, so we managed to prevent that from happening (if that does sound sick to you, you are not alone).
But one of the biggest productivity killers was the incredible amount of time it took WinForms designer to open complex forms, e.g. forms with lots of controls spread over several tabpages. It lasted minutes of up to 100% CPU usage on typical developer machines in 2003 (remember, no dualcores back then) and required close to a Gigabyte of additionally allocated memory. Sometimes the IDE crashed during the process and we had to start all over. I blamed the third-party controls we used. They probably misbehaved at design time. Never would Microsoft have left such a bug unpatched for more than three years, right?
Wrong!
The following CPU and memory usage charts represent the same activity - opening our most complex form in Visual Studio 2003 WinForms designer on a dualcore Pentium 4 3.0GHz with 2 Gigs of RAM.
Visual Studio 2003 w/o SP1: 90 seconds, memory allocation 800MB:
(Core 1) (Core 2) (Memory)Visual Studio 2003 SP1: 10 seconds, memory allocation 20MB:
(Core 1) (Core 2) (Memory)
Tuesday, August 22, 2006
Test Automation For .NET Winforms Applications
I had been searching for a decent test automation tool for one of our .NET client/server applications for quite a while now.
Of course there is NUnit for unit testing, but our application is very userinterface-heavy, and while we will continue to provide NUnit test cases, they only cover one part.
Then there are the big players in user interface test automation like Rational Robot or Mercury QuickTest. But the licensing costs seemed disproportional here.
We actually have applied some of those tools on other, larger projects, e.g. I used to work on an Enterprise Java solution where one of my colleagues was solely responsible for maintaining and running a suite of test cases (Rational Robot mainly). For Java web as well as Swing rich client applications there is Apache JMeter, but I don't know of any .NET port. HttpUnit allows for testing at HTTP level by emulating browser behaviour. In .NET land we now have Microsoft Software Tester Team Center for Visual Studio 2005 / .NET 2.0. I am very impressed with what I have seen about Team System in general, but in this project we are stuck with .NET 1.1 at the moment.
One product I was particularly interested in just was a real pain in getting it up and running - downloading and registering additional plugins, just do find out it wouldn't work, that kind of stuff. So I gave up on that one. Of course, this vendor will have a sales representative call in some days after you filled in the download form. All I wanted was to download the trial version (if they ask for my email that's OK, but having to enter my phone number usually is a warning sight), and have it up and running within five minutes so I can start playing around. If that's not possible, it's a no-go.
Besides I only digged out some half-baked freeware solutions for .NET. Of course, as .NET WinForms are based on native window handles, any Win32 user interface test tool might have been fine as well. User-drawn controls are a little problem, as the test tools cannot attach to any handles of child controls, so they will only record screen coordinates on mouse-events. E.g. if your pulldown menu is user-drawn (the whole menu is represented by one single Window handle, but there isn't a Window handle for each menu item), and you add another menu item on top of others, your mouse-click coordinates won't fit any more.
Anyway, one of my colleagues finally stumbled upon AutomatedQA TestComplete. It was easy to use from the first moment on, came with all the features we need, had strong scripting capabilities, and was labeled at a fair price (USD 499 for the standard edition). Right now we are in the process of assembling a little test script library, and we are recording our first test cases. After a test case has been run, the script continues to check the database for valid processing. We are planing to run those scripts automatically each night on the latest source version.
I will continue to report about our experiences with TestComplete.
Of course there is NUnit for unit testing, but our application is very userinterface-heavy, and while we will continue to provide NUnit test cases, they only cover one part.
Then there are the big players in user interface test automation like Rational Robot or Mercury QuickTest. But the licensing costs seemed disproportional here.
We actually have applied some of those tools on other, larger projects, e.g. I used to work on an Enterprise Java solution where one of my colleagues was solely responsible for maintaining and running a suite of test cases (Rational Robot mainly). For Java web as well as Swing rich client applications there is Apache JMeter, but I don't know of any .NET port. HttpUnit allows for testing at HTTP level by emulating browser behaviour. In .NET land we now have Microsoft Software Tester Team Center for Visual Studio 2005 / .NET 2.0. I am very impressed with what I have seen about Team System in general, but in this project we are stuck with .NET 1.1 at the moment.
One product I was particularly interested in just was a real pain in getting it up and running - downloading and registering additional plugins, just do find out it wouldn't work, that kind of stuff. So I gave up on that one. Of course, this vendor will have a sales representative call in some days after you filled in the download form. All I wanted was to download the trial version (if they ask for my email that's OK, but having to enter my phone number usually is a warning sight), and have it up and running within five minutes so I can start playing around. If that's not possible, it's a no-go.
Besides I only digged out some half-baked freeware solutions for .NET. Of course, as .NET WinForms are based on native window handles, any Win32 user interface test tool might have been fine as well. User-drawn controls are a little problem, as the test tools cannot attach to any handles of child controls, so they will only record screen coordinates on mouse-events. E.g. if your pulldown menu is user-drawn (the whole menu is represented by one single Window handle, but there isn't a Window handle for each menu item), and you add another menu item on top of others, your mouse-click coordinates won't fit any more.
Anyway, one of my colleagues finally stumbled upon AutomatedQA TestComplete. It was easy to use from the first moment on, came with all the features we need, had strong scripting capabilities, and was labeled at a fair price (USD 499 for the standard edition). Right now we are in the process of assembling a little test script library, and we are recording our first test cases. After a test case has been run, the script continues to check the database for valid processing. We are planing to run those scripts automatically each night on the latest source version.
I will continue to report about our experiences with TestComplete.
Saturday, July 29, 2006
The Upside-Down-Ternet
So if your wannabe-hacker neighbour intents to steal bandwitdh from your WLAN, instead of using WPA you could rather turn the (ip)tables and set up his own Upside-Down-Ternet.

Friday, July 07, 2006
Gates, Jobs, And The Zen Aesthetic
Garry Reynolds compares Bill Gates' and Steve Jobs' presentation styles:
Monday, June 26, 2006
Software Engineering Radio On Model Driven Software Development
Great series of podcasts on model driven software development by the folks from Software Engineering Radio. I spend some time last weekend listening to...
... and also pointed my coworkers to those episodes in order go get all of us jump-started on MDSD, a topic which will be becoming of major importance in one of our upcoming projects.
- Episode 5: Model-Driven Software Development (Part 1)
- Episode 6: Model-Driven Software Development (Part 2)
- Episode 16: Model-Driven Software Development (Part 3 / Hands-On)
... and also pointed my coworkers to those episodes in order go get all of us jump-started on MDSD, a topic which will be becoming of major importance in one of our upcoming projects.
Friday, June 16, 2006
Ruby On Rails
If you are developing web applications under J2EE just like me, and also grew increasingly curious about all that hype around Ruby on Rails lately, you might want to have a look at the screencasts available at rubyonrails.org. Having watched some of the presentations, it's certainly too early to draw any conclusions yet. All I can say is that Ruby on Rails looks like an extremely productive environment. Hacking prototypes that way seems like a very natural thing to do. On the other hand, there is a lot of magic going on. And I don't like magic, at least not too much of it. I am also one of those old-fashioned developers who prefer to pass their code through a compiler before running it. Still, I will definitely take a closer look on Ruby on Rails as soon as my schedule allows me to.
Thursday, June 15, 2006
Gates To Leave Day-To-Day Role At Microsoft
News of the day: Microsoft announced Thursday that chairman and co-founder Bill Gates will transition out of a day-to-day role at the company, effective July 2008, to spend more time working on his charitable foundation.
Having read a lot on Bill Gates' biography over the years, I am a little bit surprised by this step. He had been showing such a lot of drive and dedication for the software business for more than thirty years. The people who challenged him, Gary Kildall (DR), Mitch Kapor (Lotus), Ray Noorda (Novell), Jim Cannavino (IBM), Philippe Kahn (Borland), all of them kissed the dust sooner or later. I am not sure about Eric Schmidt and Google yet ;-) Anyway, and whether people like it or not, Gates is leaving the ring as undisputed champion.
Having read a lot on Bill Gates' biography over the years, I am a little bit surprised by this step. He had been showing such a lot of drive and dedication for the software business for more than thirty years. The people who challenged him, Gary Kildall (DR), Mitch Kapor (Lotus), Ray Noorda (Novell), Jim Cannavino (IBM), Philippe Kahn (Borland), all of them kissed the dust sooner or later. I am not sure about Eric Schmidt and Google yet ;-) Anyway, and whether people like it or not, Gates is leaving the ring as undisputed champion.
Sunday, June 11, 2006
Dolphin Filemanager For KDE
My friend Peter has now published a first alpha version of his Linux filemanager codenamed "Dolphin". It is being implemented in C++, based on Qt. I know Peter's works from several years of joined efforts on a C++ framework, so I can really recommend Dolphin to Linux desktop users in KDE camp. Unlike Konqueror, Dolphin supports file operations exclusively and emphasizes on usability and performance.
Please give it a try, and tell Peter what you think about it.
Please give it a try, and tell Peter what you think about it.
Subscribe to:
Posts (Atom)